用 Elastic 可观测性实现云原生应用监控(1/4)
在本系列文章中,我们将学习如何使用 Elastic Stack 来实现对云原生应用的监控。该解决方案具有完备的日志、指标、APM 和可用性采集能力,可以在大规模/云原生的环境下,完成服务质量目标(SLO)的管理。 总的来说主要包括3个方面:
Metrics:通过收集系统各个组件的时序数据,比如 CPU、内存、磁盘、网络等信息,通常可以用来显示系统的整体状况以及检测某个时间的异常行为;
Logging:通过日志收集工具(如Filebeat,Fluentd等)收集系统日志,将用户的数据索引到 Elasticsearch 中并在 Kibana 中进行可视化;
Tracing:通过使用APM(应用性能监控)工具收集服务执行的每一个请求和步骤(比如 HTTP 调用、数据库查询等),通过追踪这些数据,我们可以检测到服务的性能,并相应地改进或修复我们的系统。
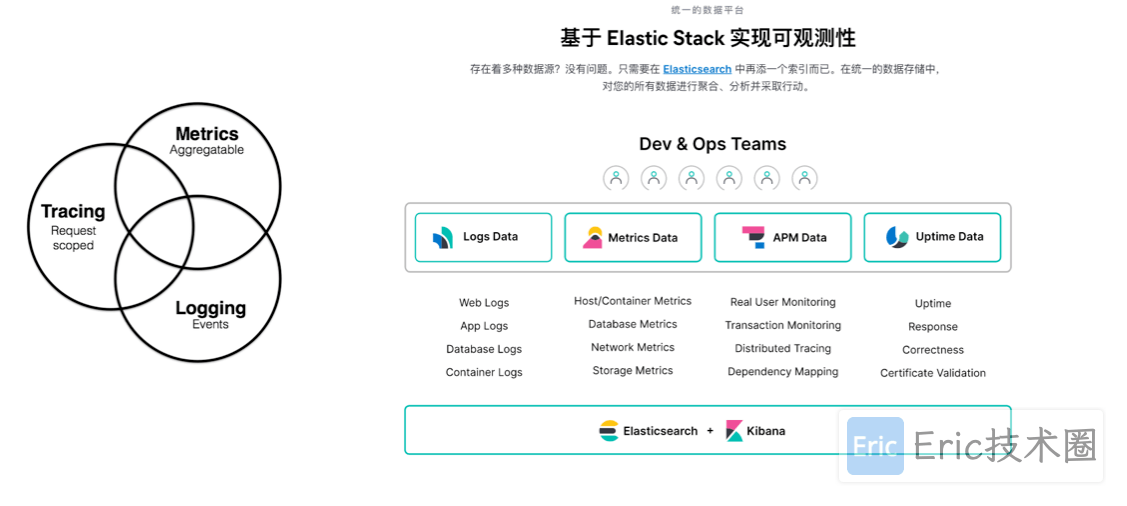
为啥我们需要实现软件系统的可观察性呢?
当今软件环境复杂性所提出的要求
谈及当今的部署环境,我们有许多方面需要考虑。无论是本地部署数据中心、公共云基础架构还是混合架构,我们都可用于运行应用程序和服务。当今任何一个典型环境中都具备一个编排层(例如 Kubernetes),用于实现应用程序的自动部署和扩展。我们已经有可用于运行应用程序的事物,例如容器、虚拟机或裸机。在开发应用程序时,我们容易对第三方系统产生依赖,例如外部服务、数据库或我们所在组织中其他团队编写的组件。
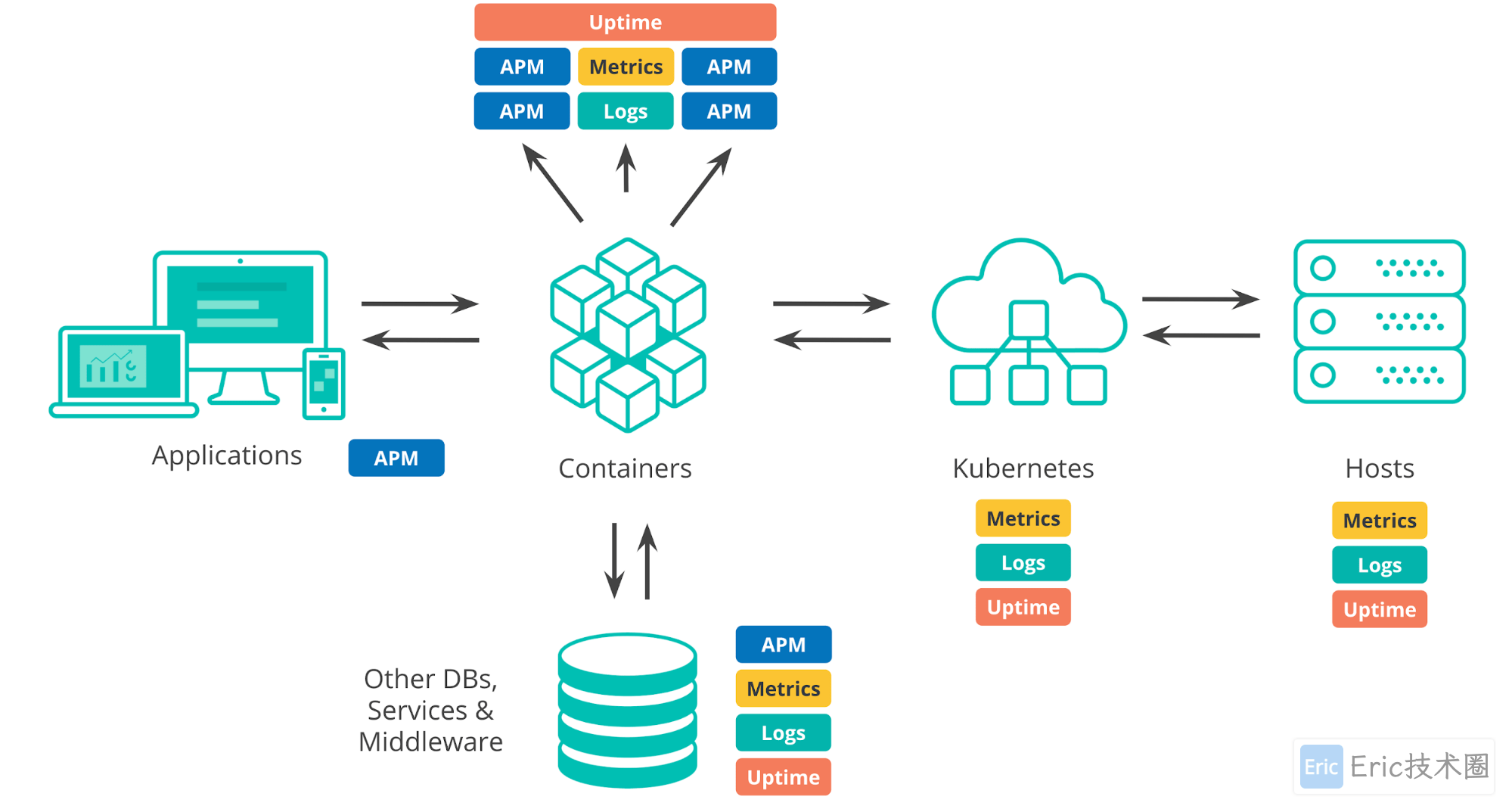
为确保应用程序正常运行,我们需要监测其中所有不同组件。这些组件会产生大量监测数据,不仅包括日志和指标,还包括 APM 和运行时间数据。
接下来我们就来学习下如何使用 Elastic Stack构建云原生应用监控。这里的试验环境是 Kubernetes v1.18.4 版本的集群,第一篇我们将创建ElasticSearch集群以及Kibaba可视化应用,下面创建一个名为 elastic 的命名空间,方便将所有的资源对象都部署在一起:

ElasticSearch 安装
这里只演示单节点全部Role的部署,若想要安装企业级的ElasticSearch集群,可以参考下图,针对不同Role:master,ingress,data分别启动ElasticSearch应用,每个角色可以分配自己的资源,如Replicas,CPU,Memory,Storage等。
修改ElasticSearch官方Helm Values文件,并保存为es-values.yaml
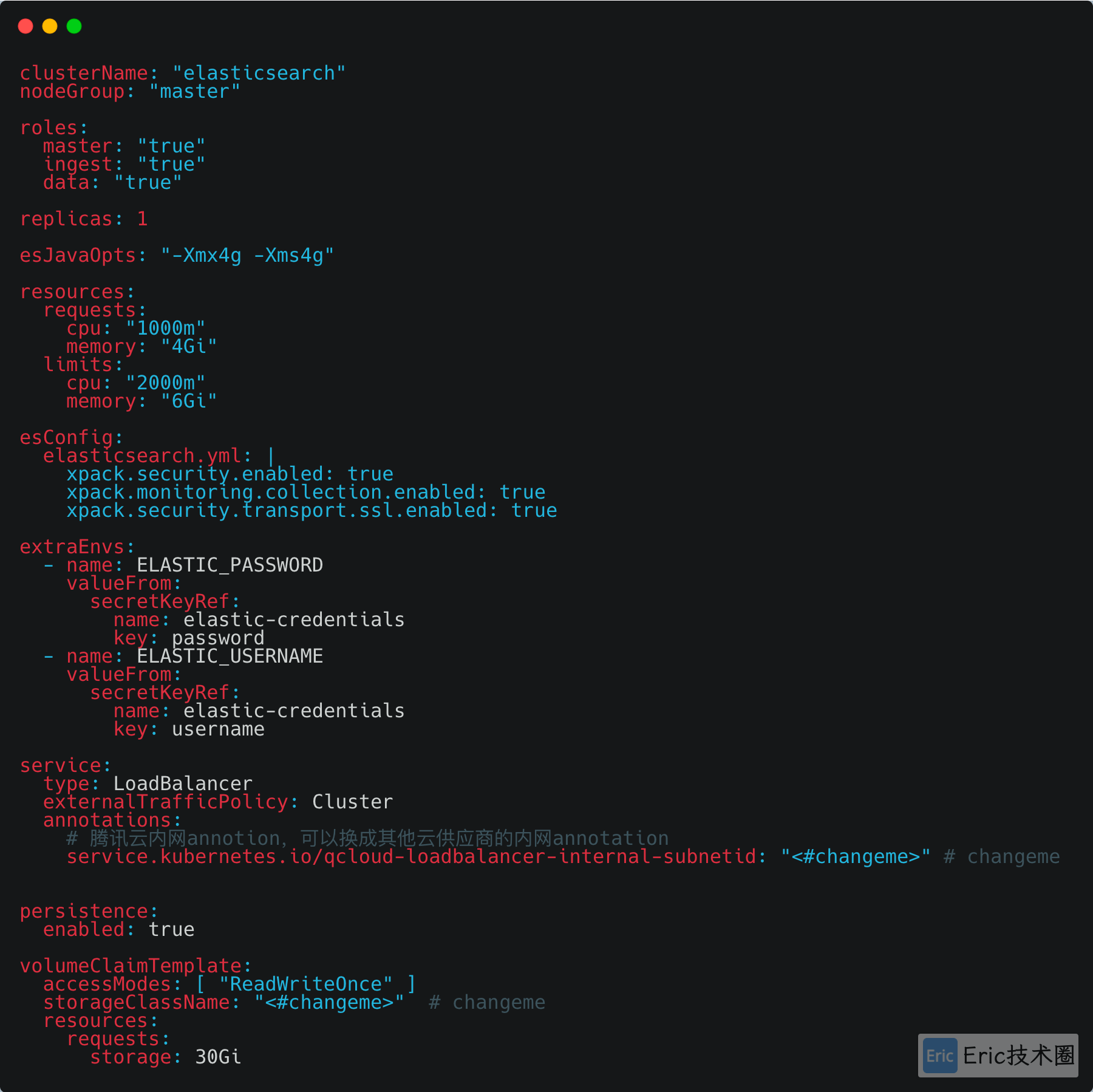
使用Helm安装ElasticSearch:

创建连接ElasticSearch的认证账号信息:

如果出现镜像无法下载的情况,在es-values.yaml中加入mirror的镜像:
image: "amuguelove/elasticsearch"
imageTag: "7.13.0"同理下面的官方Kibana镜像。
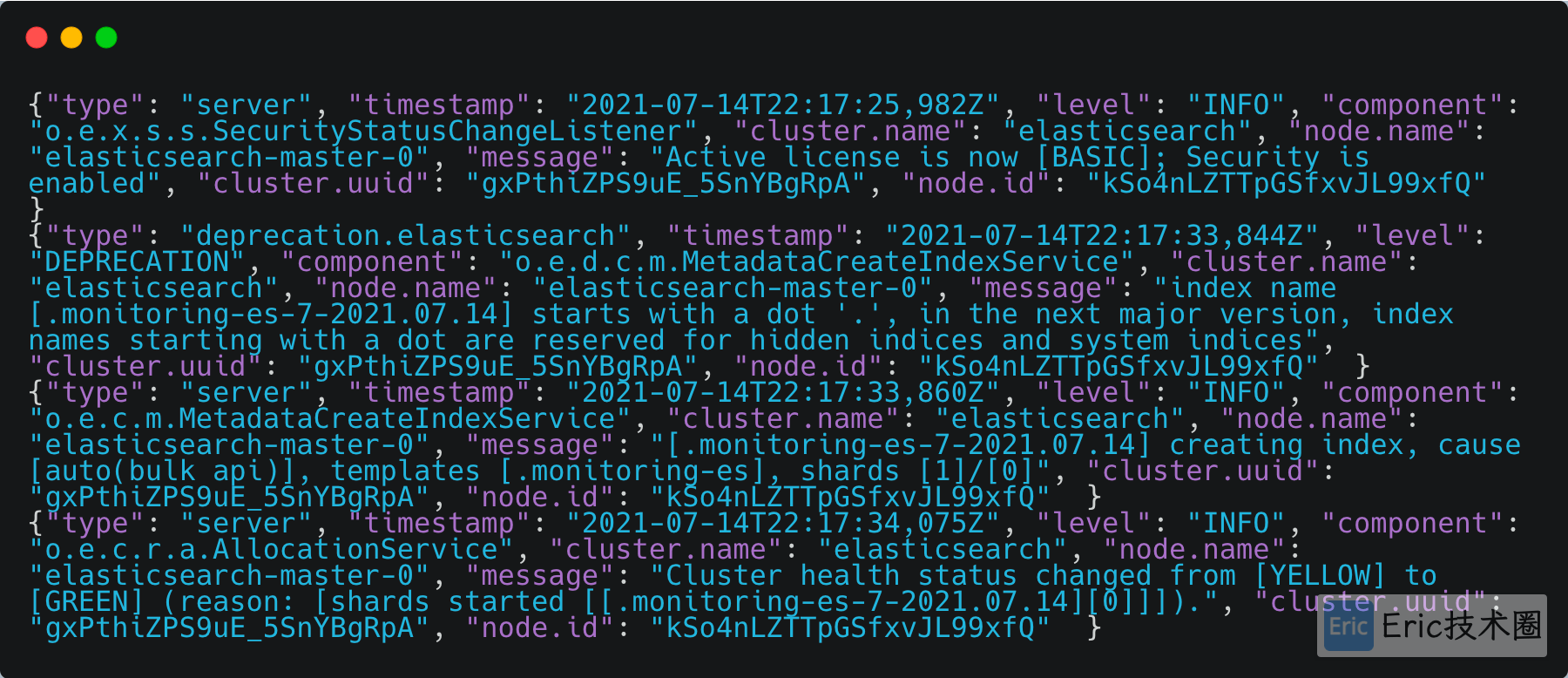
出现如下日志,status changed from [YELLOW] to [GERRN],证明ElasticSearch安装成功:
Kibana安装
修改Kibana官方Helm Values文件,并保存为kibana-values.yaml:
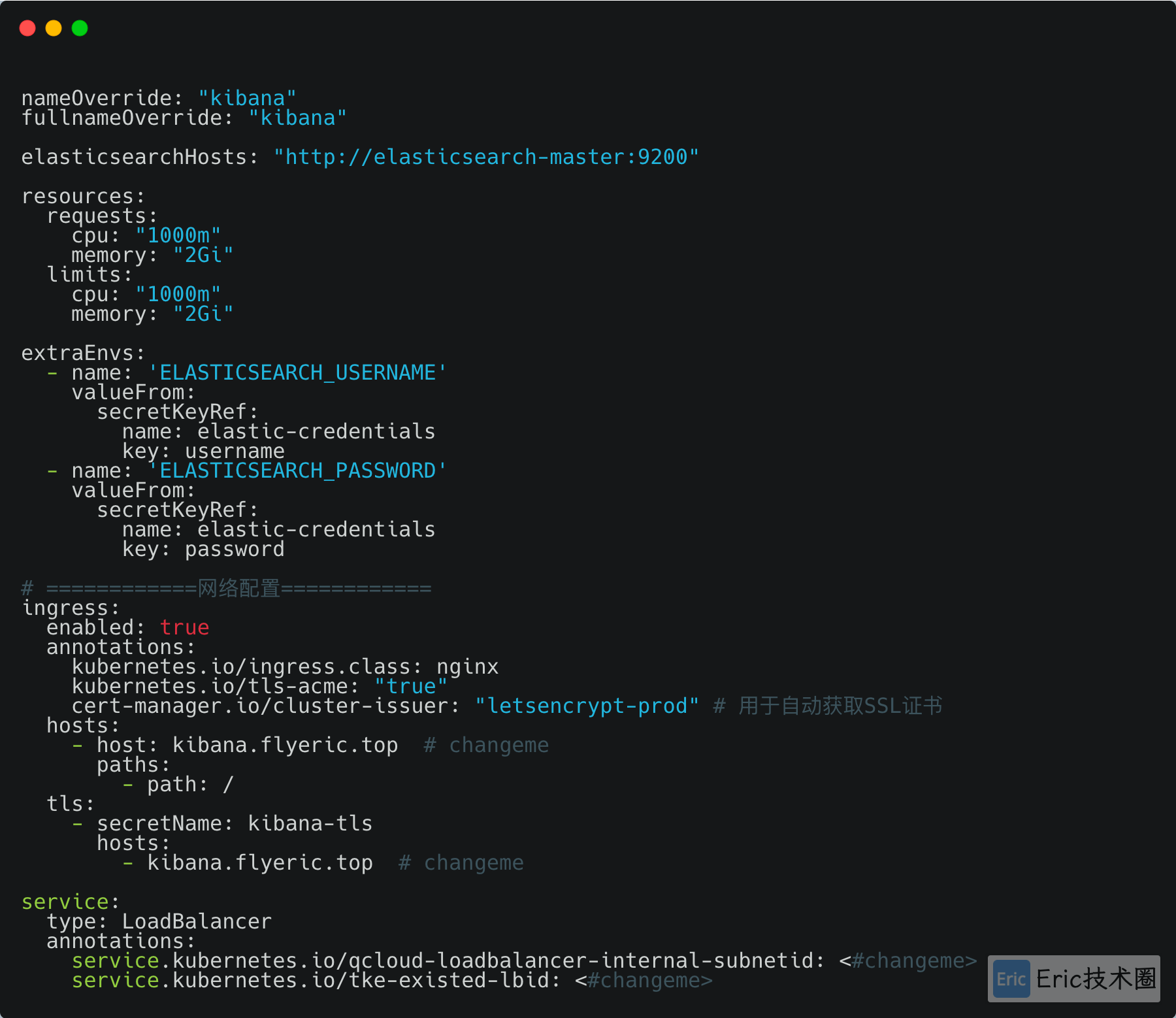
Helm安装脚本:

查看Pod启动情况:

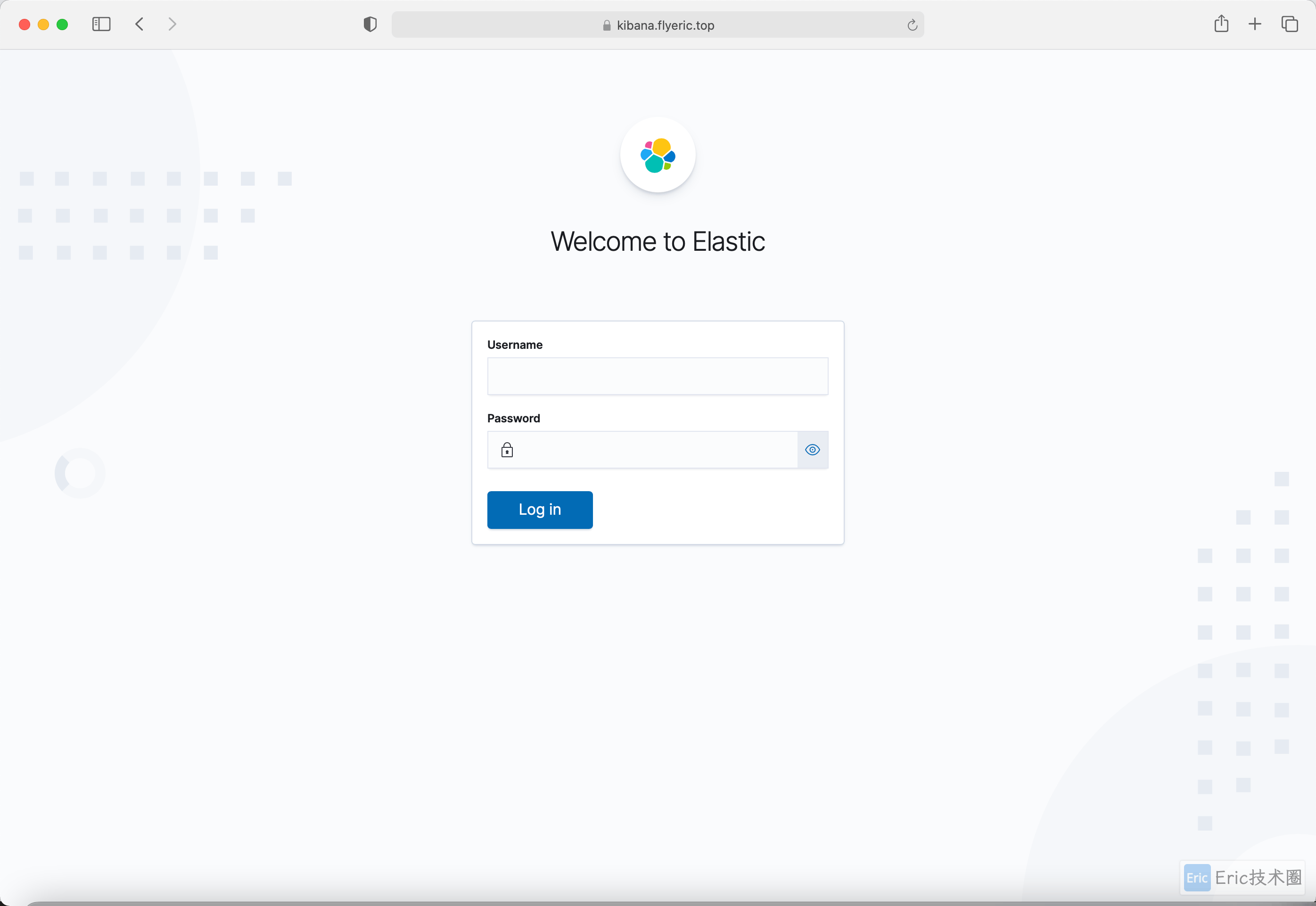
如下图所示,使用上面我们创建的 Secret 对象的用户和密码即可登录:
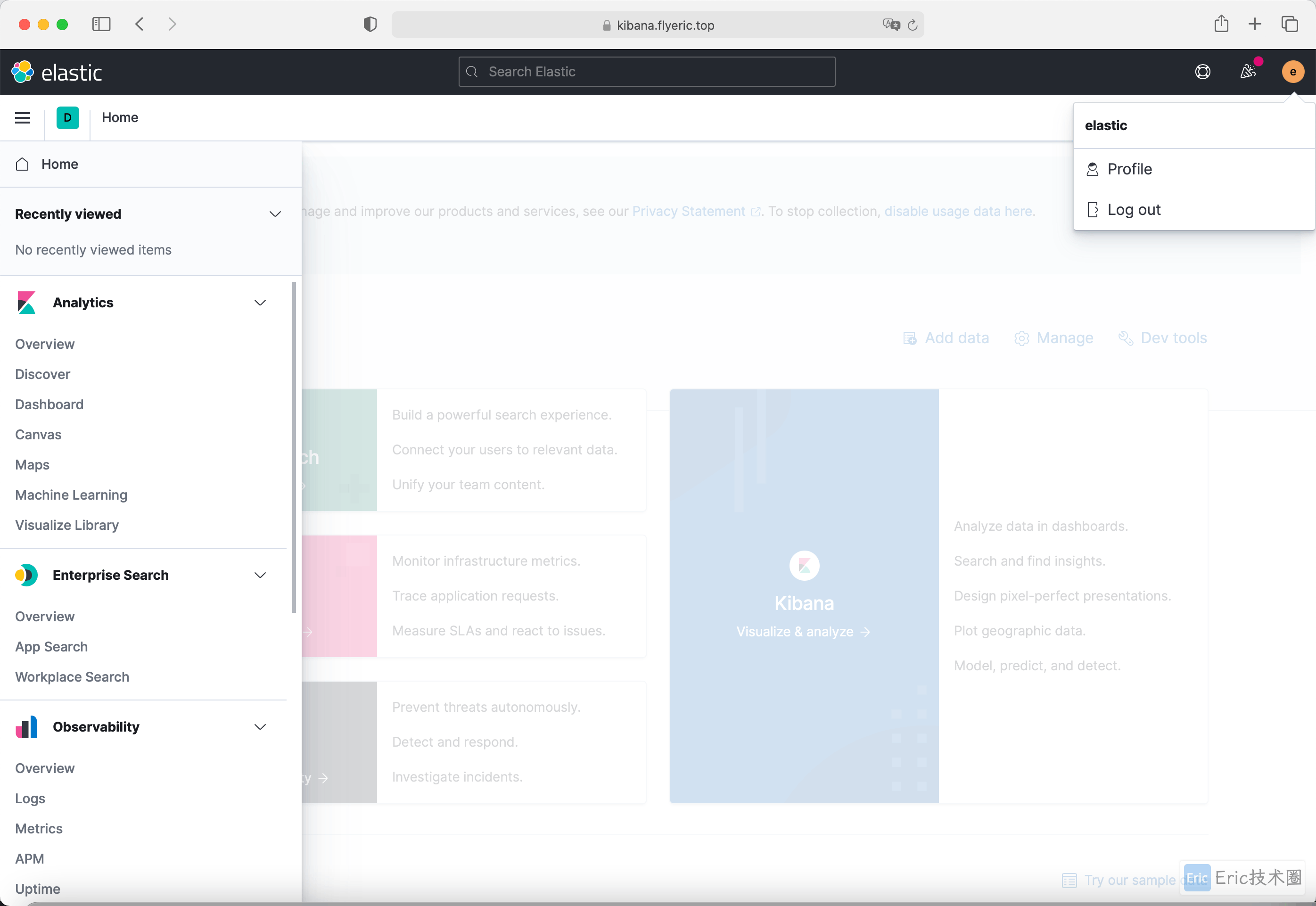
登录成功后会自动跳转到 Kibana 首页:
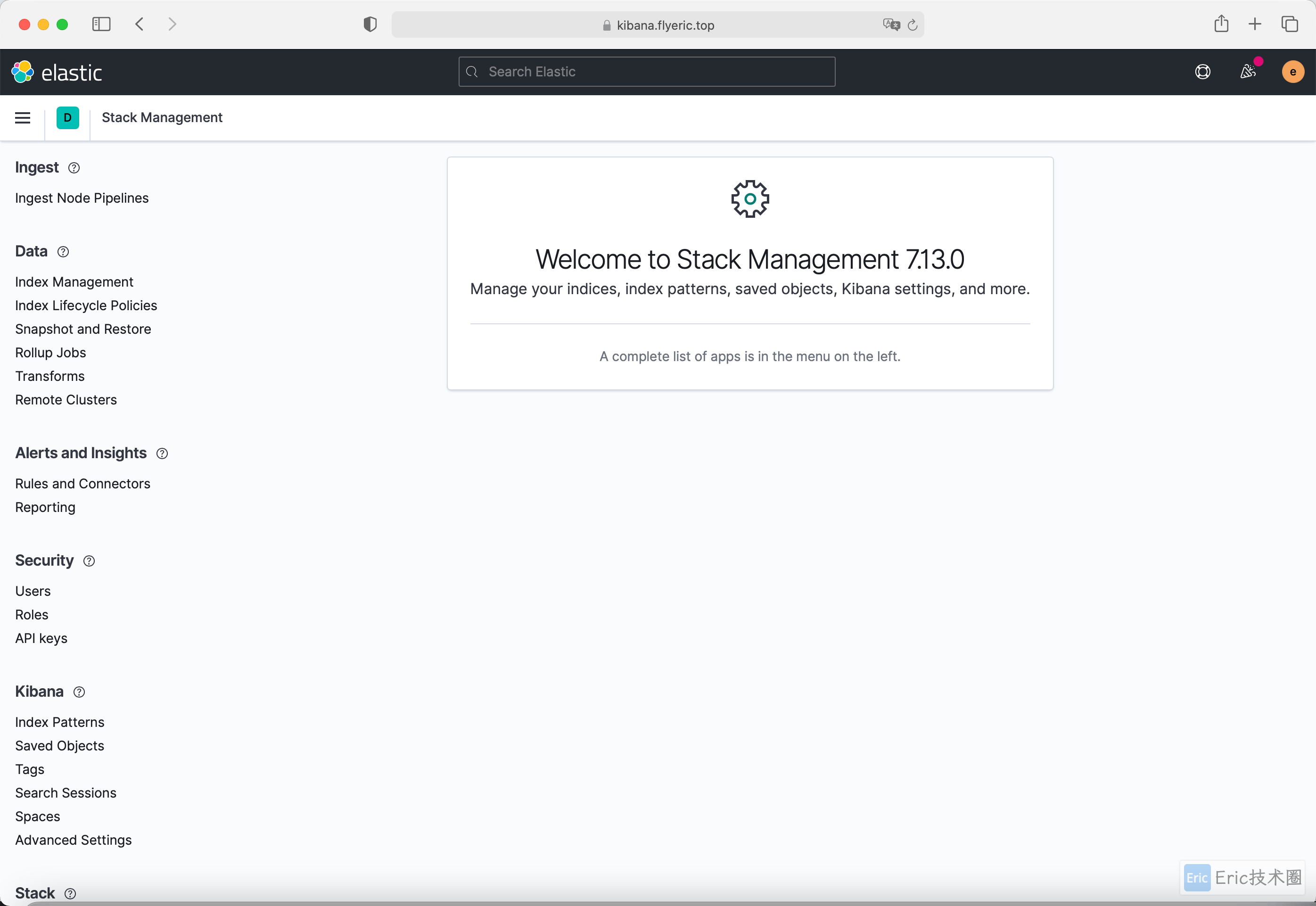
显示Kibana版本:
还可以通过 左上角图标 → Stack Monitoring 页面查看整个集群的健康状态:
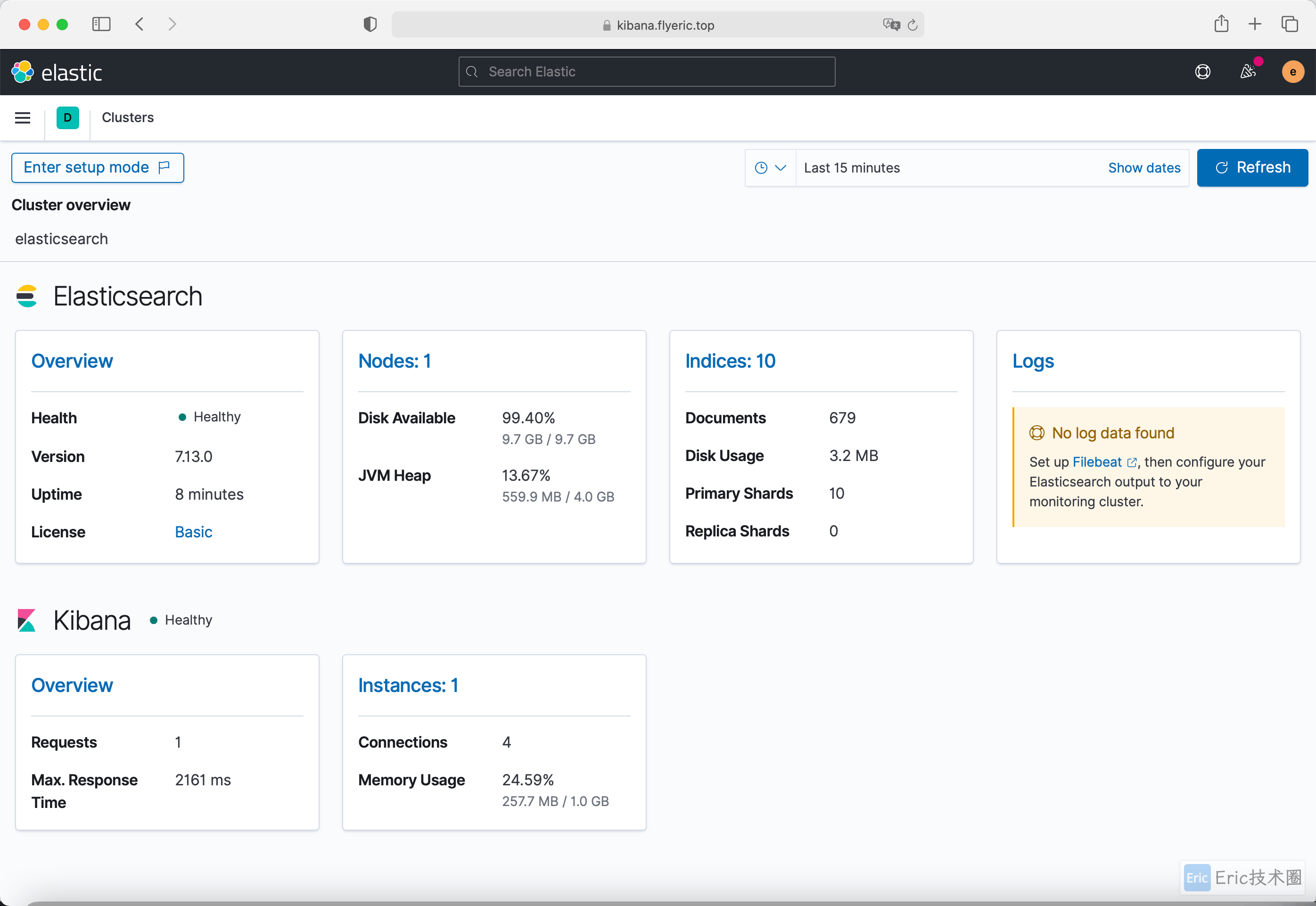
到此为止我们成功安装了 ElasticSearch 与 Kibana,它们将为我们来存储和可视化我们的应用数据(日志,监控指标和追踪)服务。
在下一篇文章中,我们将来学习如何安装和配置 Fluentd/Fluent Bit,并将日志传入ElasticSearch中,Kibana可视化出来。
Reference
Elastic 官网:https://www.elastic.co
Elastic 可观测性:https://www.elastic.co/cn/observability
Helm 官网:https://helm.sh
借助Elastic可观测性解决方案检测基础架构和微服务:https://www.elastic.co/cn/blog/monitoring-infrastructure-and-microservices-with-elastic-observability