AI 辅助编程:VS Code + Cline + DeepSeek
见字如面,与大家分享实践中的经验与思考。
通过 VS Code + Cline + DeepSeek 以一个实际项目为例,进行项目的通读理解以及新增功能,并能够解决代码的扩展性以及过程中的问题修复,最后可以正常运行和演示。
项目技术栈如下:
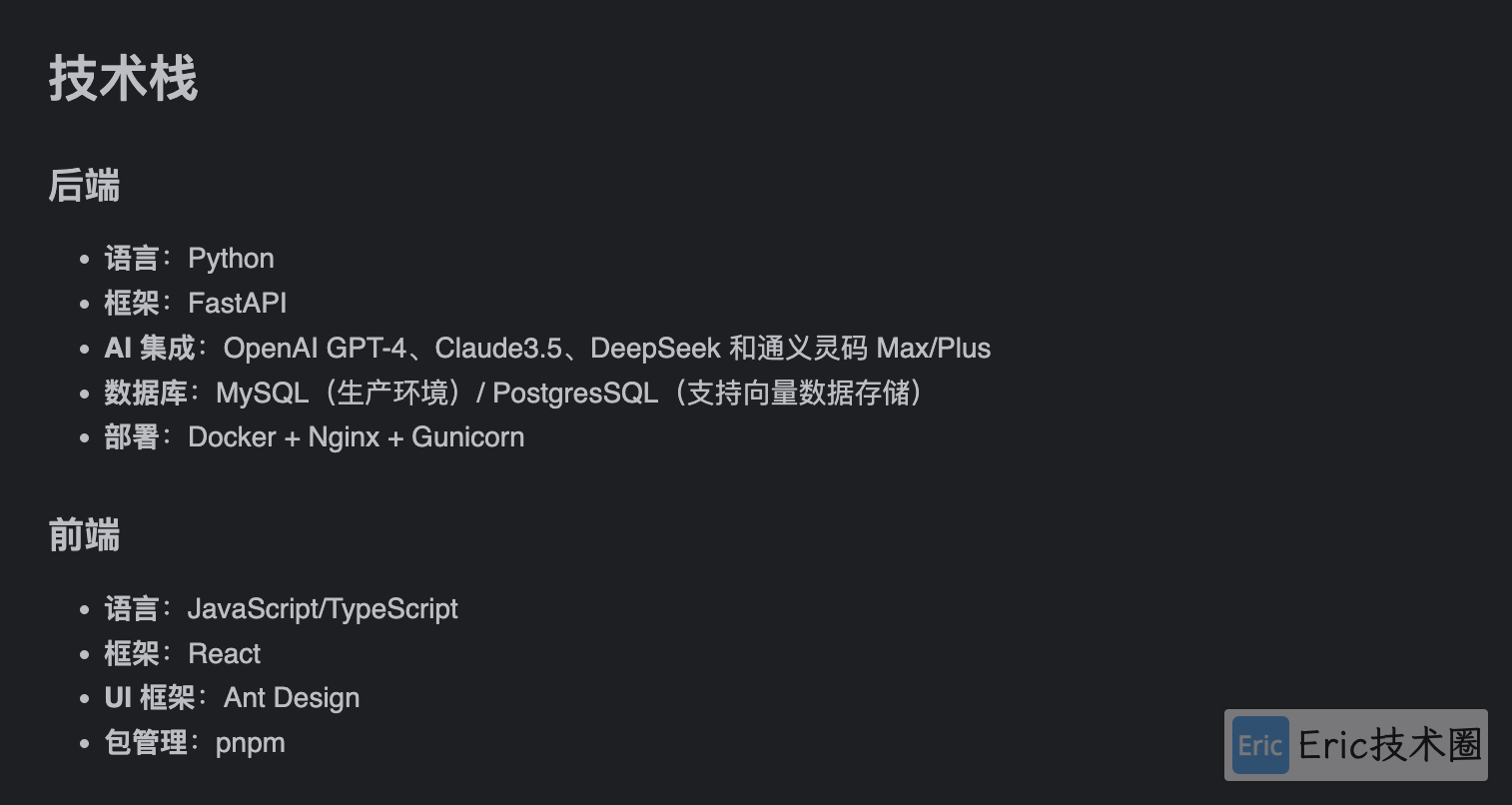
项目的具体情况可以看下面 AI 总结的项目总体概览。
安装 Cline
需要先安装 VS Code(全称:Visual Studio Code)
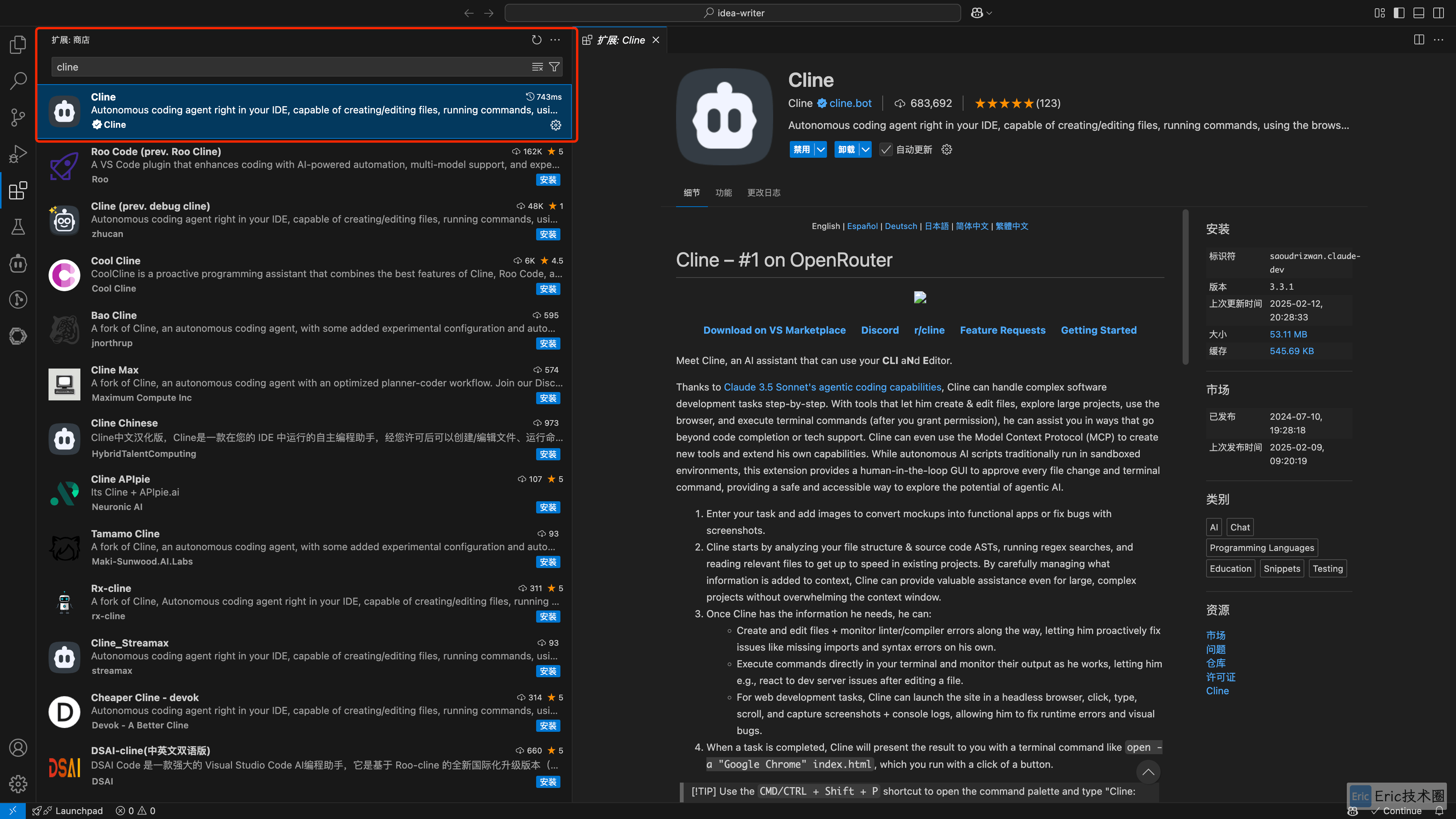
配置 Cline
在VS Code中,通过 Ctrl/Command+Shift+P 打开命令工具,在新 tab 中打开 Cline 进行配置。或者通过左边的图标进入 cline。
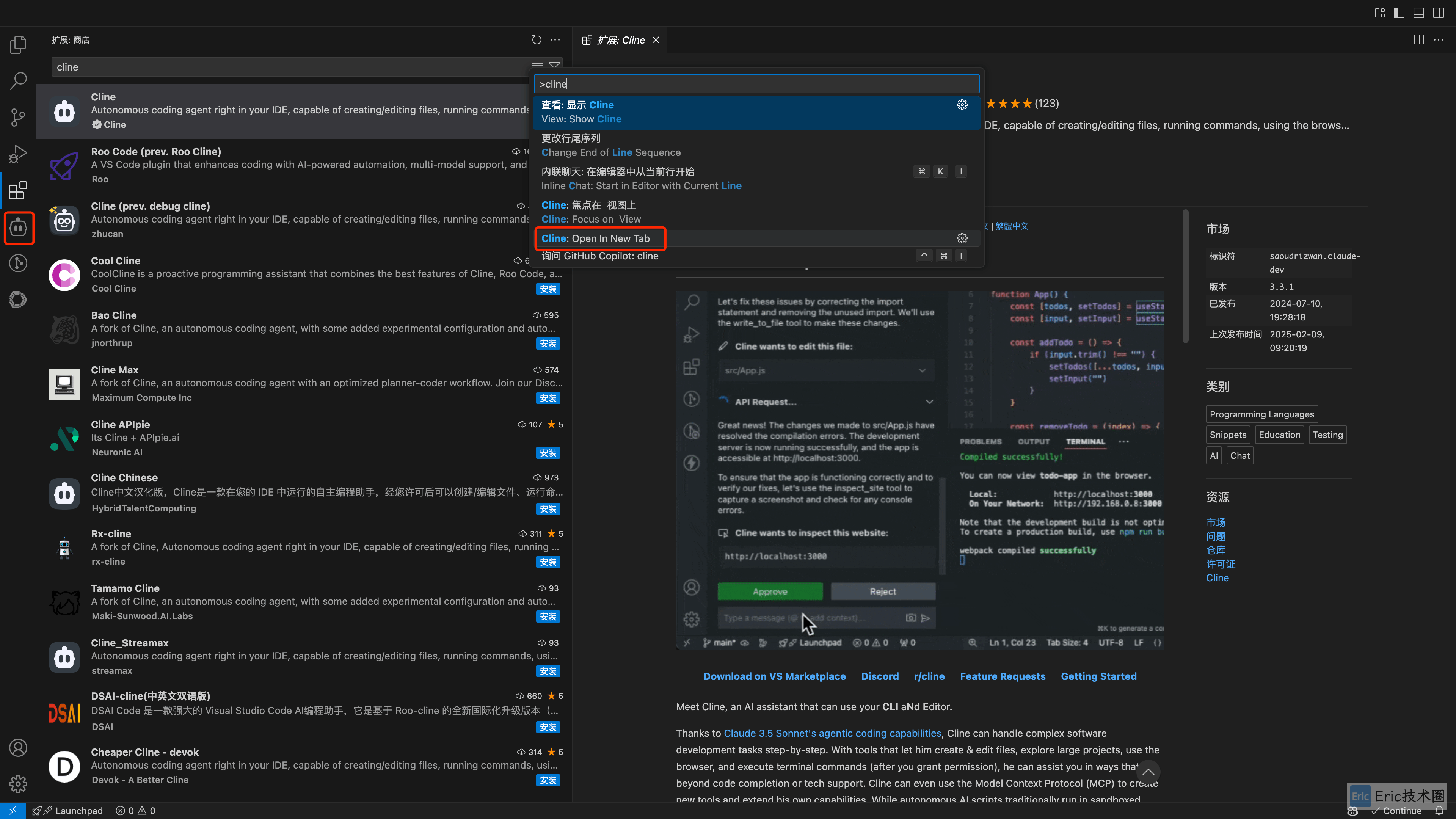
01、配置 DeepSeek
这里有很多 AI Provider 的选择,如下图:
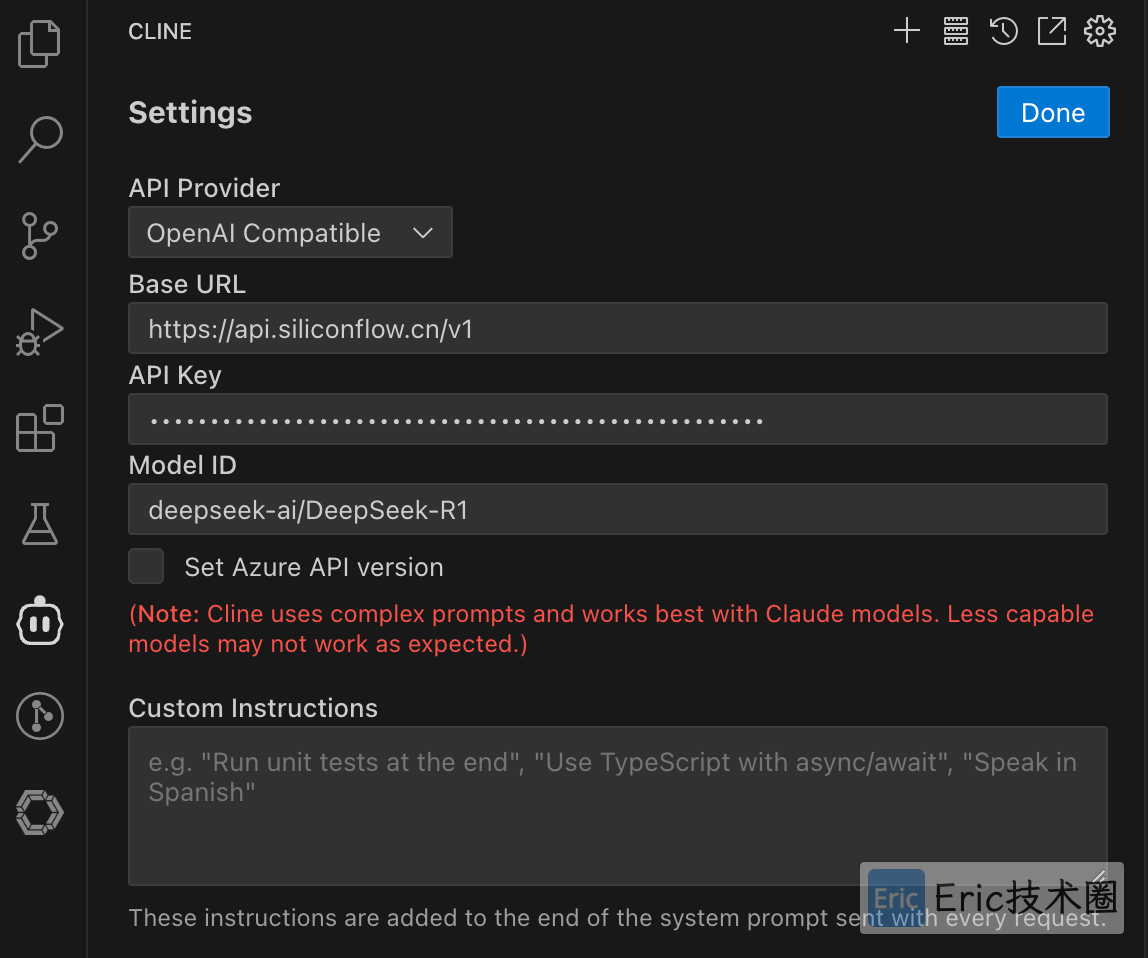
硅基流动:
API Provider:选择 “OpenAI Compatible”
Base Url:https://api.siliconflow.cn/v1
API Key:从 https://cloud.siliconflow.cn/account/ak 中获取
Model ID:从 https://cloud.siliconflow.cn/models 中获取
阿里云百炼:
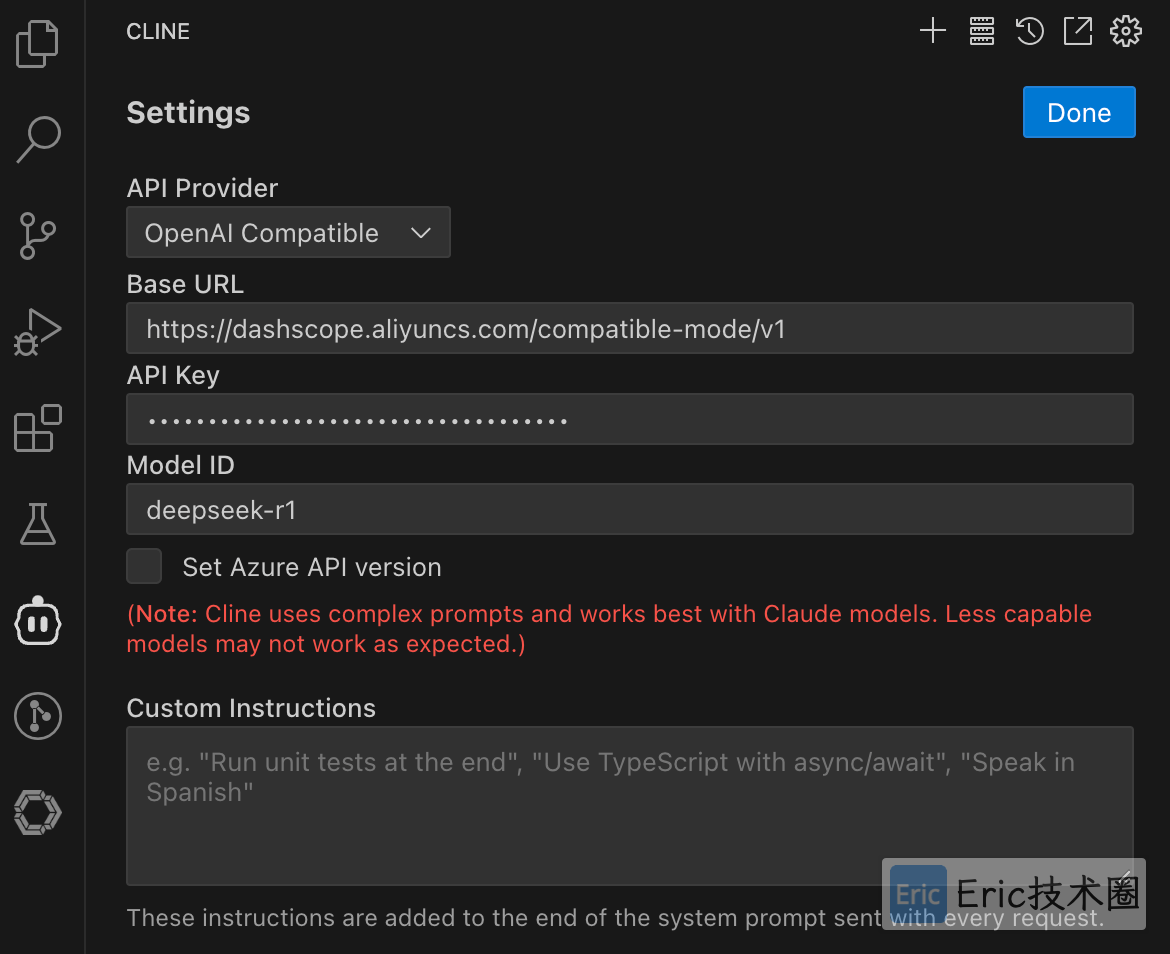
API Provider:选择 “OpenAI Compatible”
API Key:从https://bailian.console.aliyun.com/?apiKey=1#/api-key 中获取
Model ID:从 https://bailian.console.aliyun.com/#/model-market 中获取
以上两种方式都有一定的免费额度,都可以快速和免费地体验。但在使用硅基流动时,非常卡顿,后面切换到了阿里云百炼平台。
02、配置权限
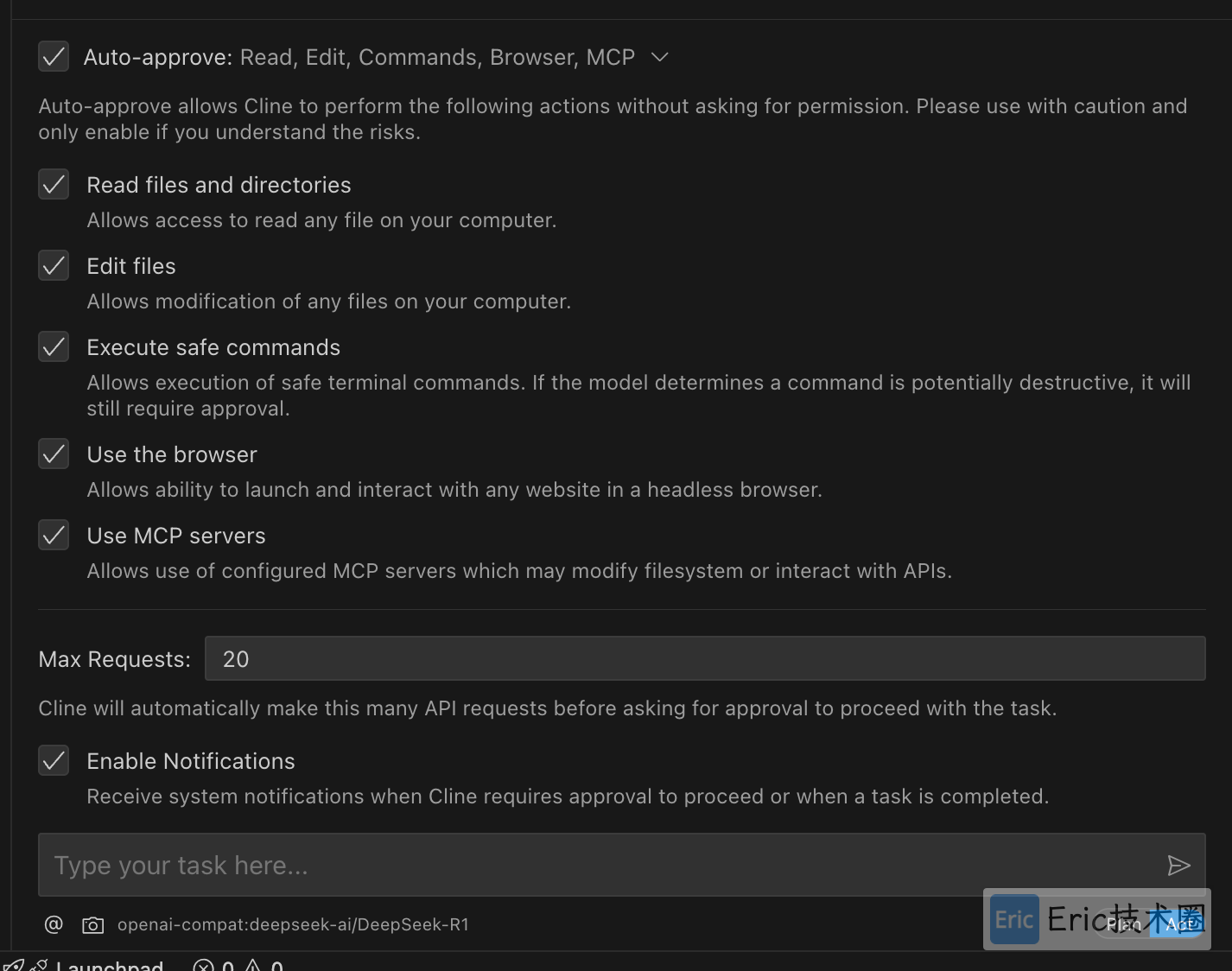
注意:如果你开通了 Auto-approve,cline将会自动移动、删除、修改你的文件。如果不勾选的话,每次修改之后需要人工介入同意或者拒绝这次修改。
Cline使用的几种方式:Problems、文件、文件夹 + 提问,当然也可以进行自由的组合。
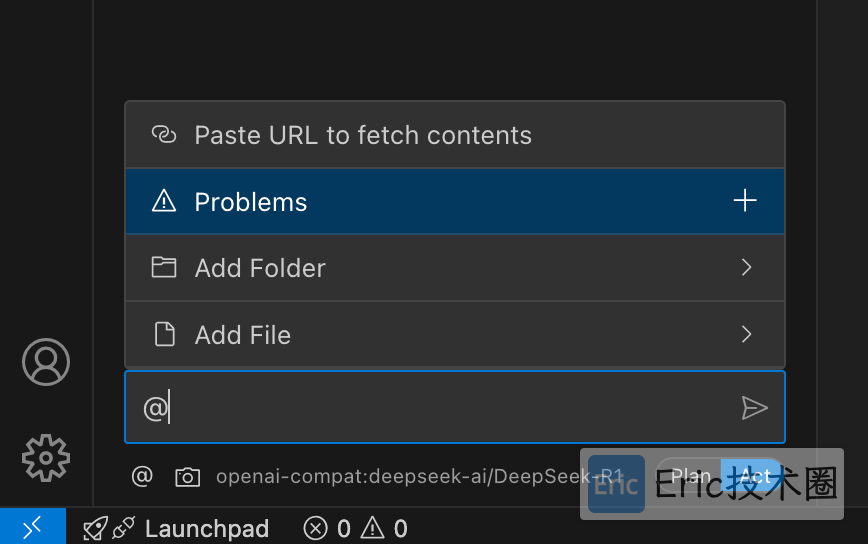
实战
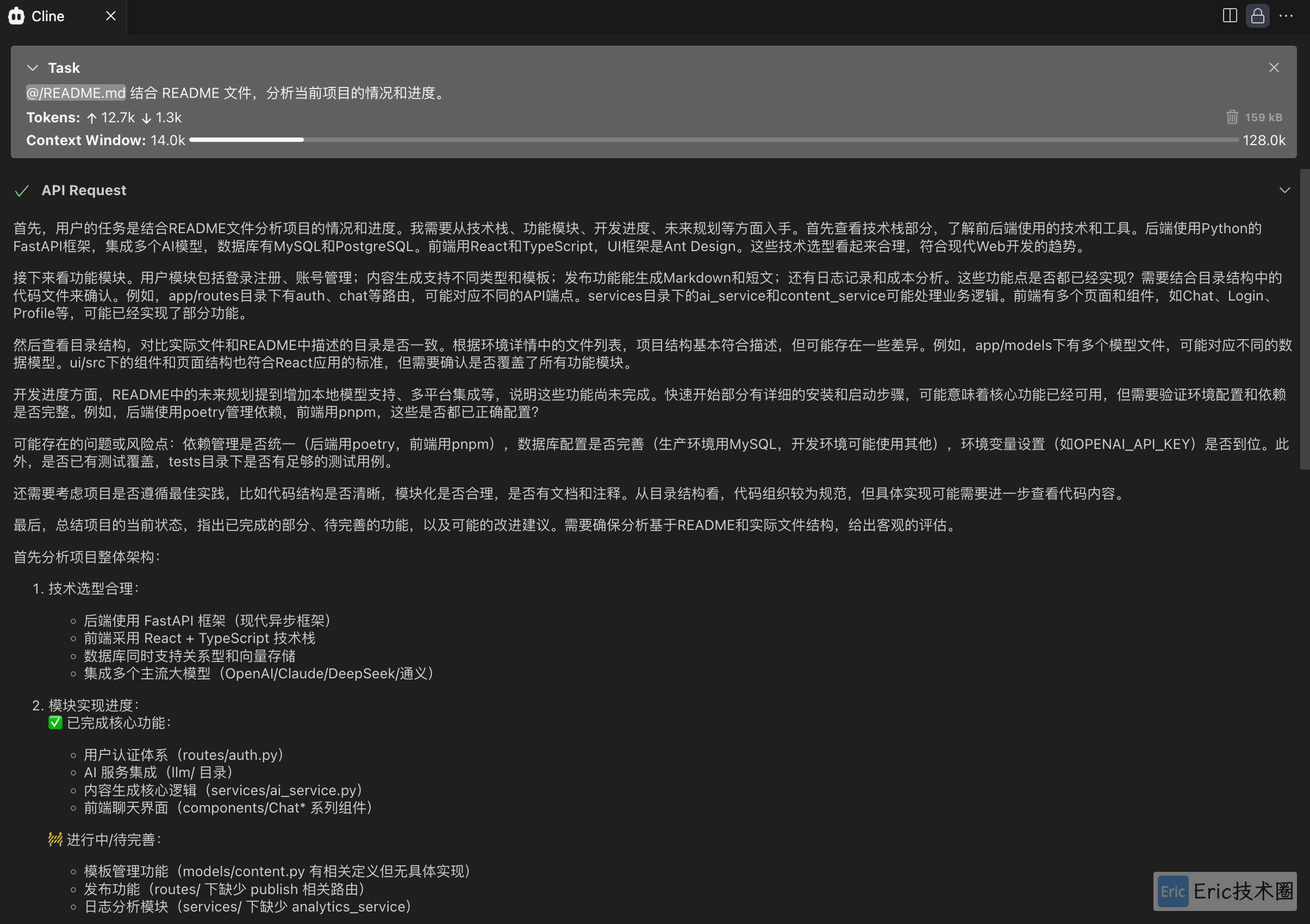
01、通读整个项目
通过 README文件 让 cline 结合 DeepSeek 说明当前项目的情况和进度。


02、新增功能:加入 DeepSeek V3 Chat 模型
该项目之前已经集成了openai llm。通过一个简单的 DeepSeek 的python 的demo例子,期望cline能够将其整合到当前的项目中。
Demo 代码:
from openai import OpenAI
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
# 初始化OpenAI客户端
client = OpenAI(
# 如果没有配置环境变量,请用百炼API Key替换:api_key="sk-xxx"
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
def main():
reasoning_content = "" # 定义完整思考过程
answer_content = "" # 定义完整回复
is_answering = False # 判断是否结束思考过程并开始回复
# 创建聊天完成请求
stream = client.chat.completions.create(
model="deepseek-r1", # 此处以 deepseek-v1 为例,可按需更换模型名称
messages=[
{"role": "user", "content": "9.9和9.11谁大"}
],
stream=True
# 解除以下注释会在最后一个chunk返回Token使用量
# stream_options={
# "include_usage": True
# }
)
print("\n" + "=" * 20 + "思考过程" + "=" * 20 + "\n")
for chunk in stream:
# 处理usage信息
if not getattr(chunk, 'choices', None):
print("\n" + "=" * 20 + "Token 使用情况" + "=" * 20 + "\n")
print(chunk.usage)
continue
delta = chunk.choices[0].delta
# 检查是否有reasoning_content属性
if not hasattr(delta, 'reasoning_content'):
continue
# 处理空内容情况
if not getattr(delta, 'reasoning_content', None) and not getattr(delta, 'content', None):
continue
# 处理开始回答的情况
if not getattr(delta, 'reasoning_content', None) and not is_answering:
print("\n" + "=" * 20 + "完整回复" + "=" * 20 + "\n")
is_answering = True
# 处理思考过程
if getattr(delta, 'reasoning_content', None):
print(delta.reasoning_content, end='', flush=True)
reasoning_content += delta.reasoning_content
# 处理回复内容
elif getattr(delta, 'content', None):
print(delta.content, end='', flush=True)
answer_content += delta.content
# 如果需要打印完整内容,解除以下的注释
"""
print("=" * 20 + "完整思考过程" + "=" * 20 + "\n")
print(reasoning_content)
print("=" * 20 + "完整回复" + "=" * 20 + "\n")
print(answer_content)
"""
if __name__ == "__main__":
try:
main()
except Exception as e:
print(f"发生错误:{e}")通过Cline进行自动代码改造之后:
from typing import List, Dict, Optional, AsyncGenerator
from openai import AsyncOpenAI
from dotenv import load_dotenv, find_dotenv
import os
import time
from .base import BaseLLM
from app.models.chat import ChatMessage
from app.core.config import logger
_ = load_dotenv(find_dotenv())
class DeepSeekLLM(BaseLLM):
# 定义模型的最大token限制
MODEL_LIMITS = {
'deepseek-v3': 4096
}
def __init__(self):
super().__init__()
self.client = AsyncOpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
async def generate(
self,
messages: list[ChatMessage],
**kwargs
) -> str:
formatted_messages = [
{"role": msg.role, "content": msg.content}
for msg in messages
]
response = await self.client.chat.completions.create(
model="deepseek-v3",
messages=formatted_messages,
stream=False,
**kwargs
)
return response.choices[0].message.content
async def chat(
self,
messages: list[ChatMessage],
**kwargs
) -> str:
return await self.generate(messages, **kwargs)
def _truncate_messages(self, messages: List[Dict[str, str]], model: str) -> List[Dict[str, str]]:
"""截断消息以适应模型的上下文长度限制"""
max_tokens = self.MODEL_LIMITS.get(model, 4096)
# 预留2000个token给响应
max_message_tokens = max_tokens - 2000
# 从最新的消息开始保留
truncated_messages = []
current_tokens = 0
for message in reversed(messages):
# 粗略估计token数(每4个字符约1个token)
estimated_tokens = len(message['content']) // 4
if current_tokens + estimated_tokens > max_message_tokens:
break
truncated_messages.insert(0, message)
current_tokens += estimated_tokens
return truncated_messages or [messages[-1]] # 至少保留最后一条消息
async def chat_stream(
self,
messages: List[Dict[str, str]],
temperature: float = 0.7,
max_tokens: int = 2000,
model: str = "deepseek-v3",
**kwargs
) -> AsyncGenerator[str, None]:
"""使用流式响应进行对话"""
logger.info("Starting DeepSeek stream chat with %s model", model)
start_time = time.time()
try:
# 截断消息
truncated_messages = self._truncate_messages(messages, model)
logger.info("Truncated messages: %s", truncated_messages)
is_answering = False # 判断是否结束思考过程并开始回复
# 创建异步流式响应
response = await self.client.chat.completions.create(
model=model,
messages=truncated_messages,
stream=True
)
# yield "思考过程:\n"
async for chunk in response:
if not chunk.choices:
continue
delta = chunk.choices[0].delta
# 处理空内容情况
if not getattr(delta, 'reasoning_content', None) and not getattr(delta, 'content', None):
continue
# if not getattr(delta, 'reasoning_content', None) and not is_answering:
# is_answering = True
# yield "完整回复: \n"
# # 处理思考过程
# if getattr(delta, 'reasoning_content', None):
# yield delta.reasoning_content
# # 处理回复内容
# elif getattr(delta, 'content', None):
# yield delta.content
if getattr(delta, 'content', None):
yield delta.content
except Exception as e:
error_msg = f"DeepSeek API 调用失败: {str(e)}"
if hasattr(e, 'response'):
error_msg += f"\nResponse: {e.response}"
logger.error(error_msg)
raise Exception(error_msg)
finally:
duration = time.time() - start_time
logger.info("DeepSeek stream completed | duration=%.2fs", duration)
完成之后的项目结构如下,其中 deepseek_llm.py 为主要生成的代码。
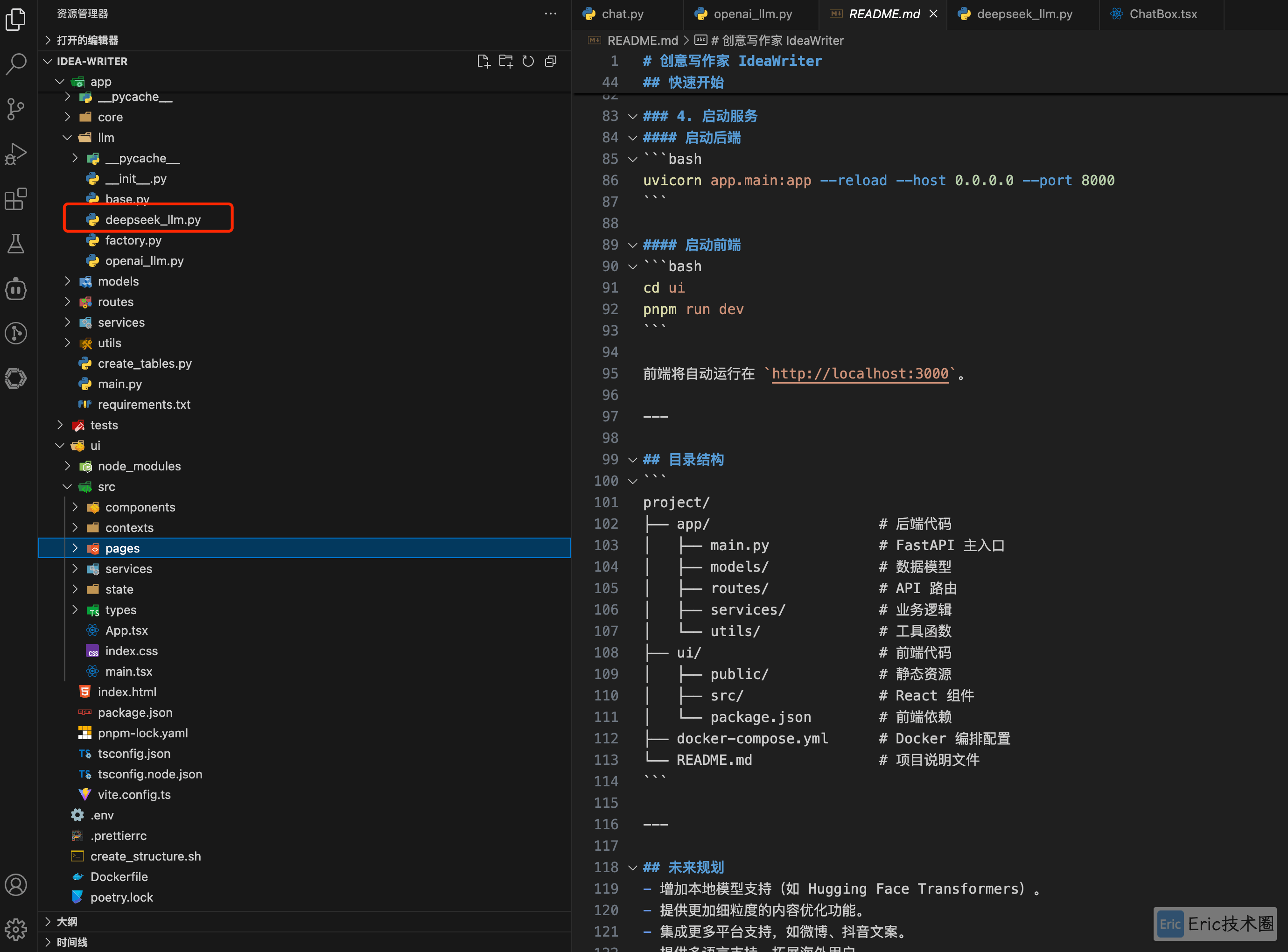
03、验证结果
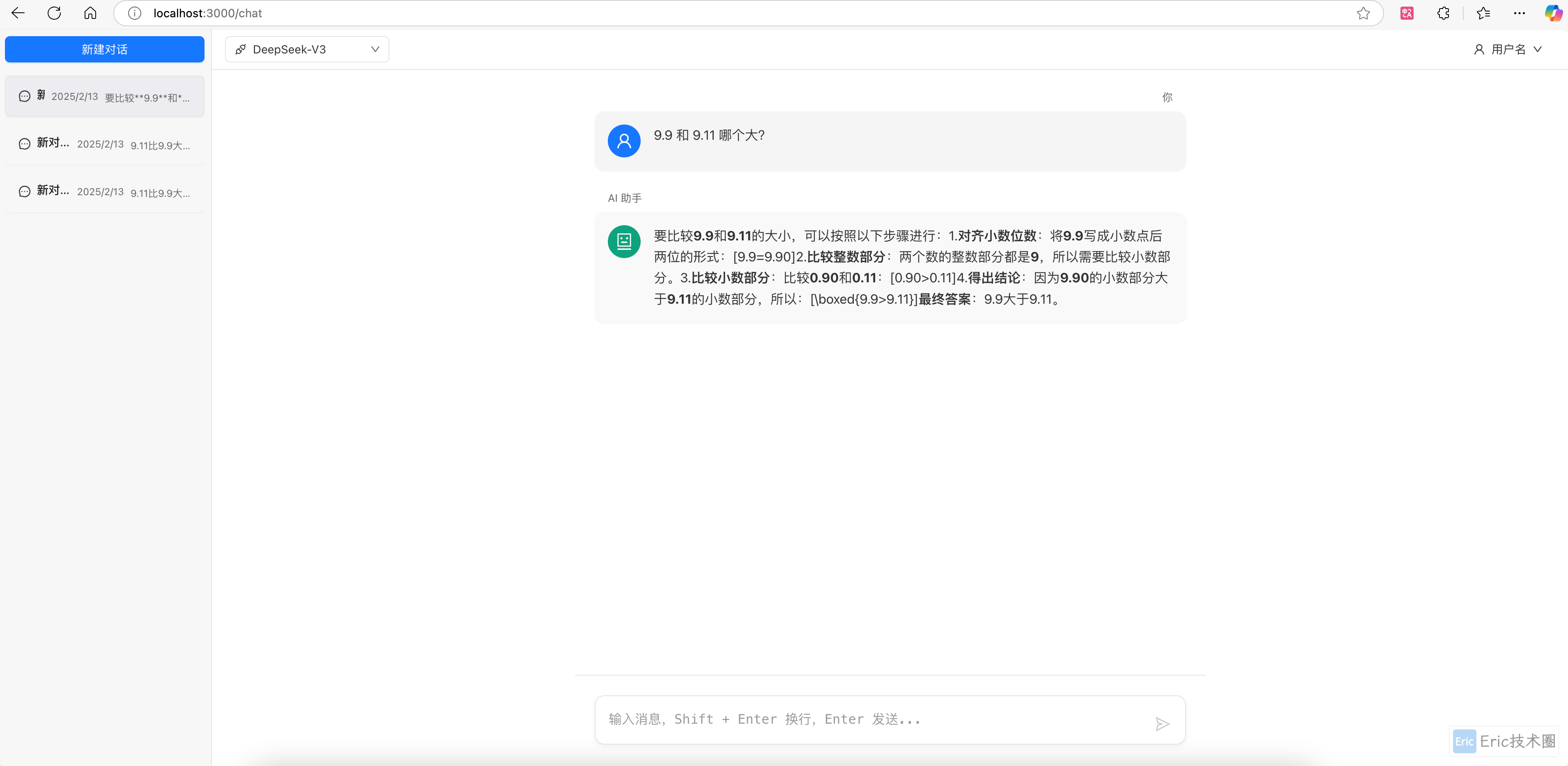
提问:9.9 和 9.11 哪个大?
首页:
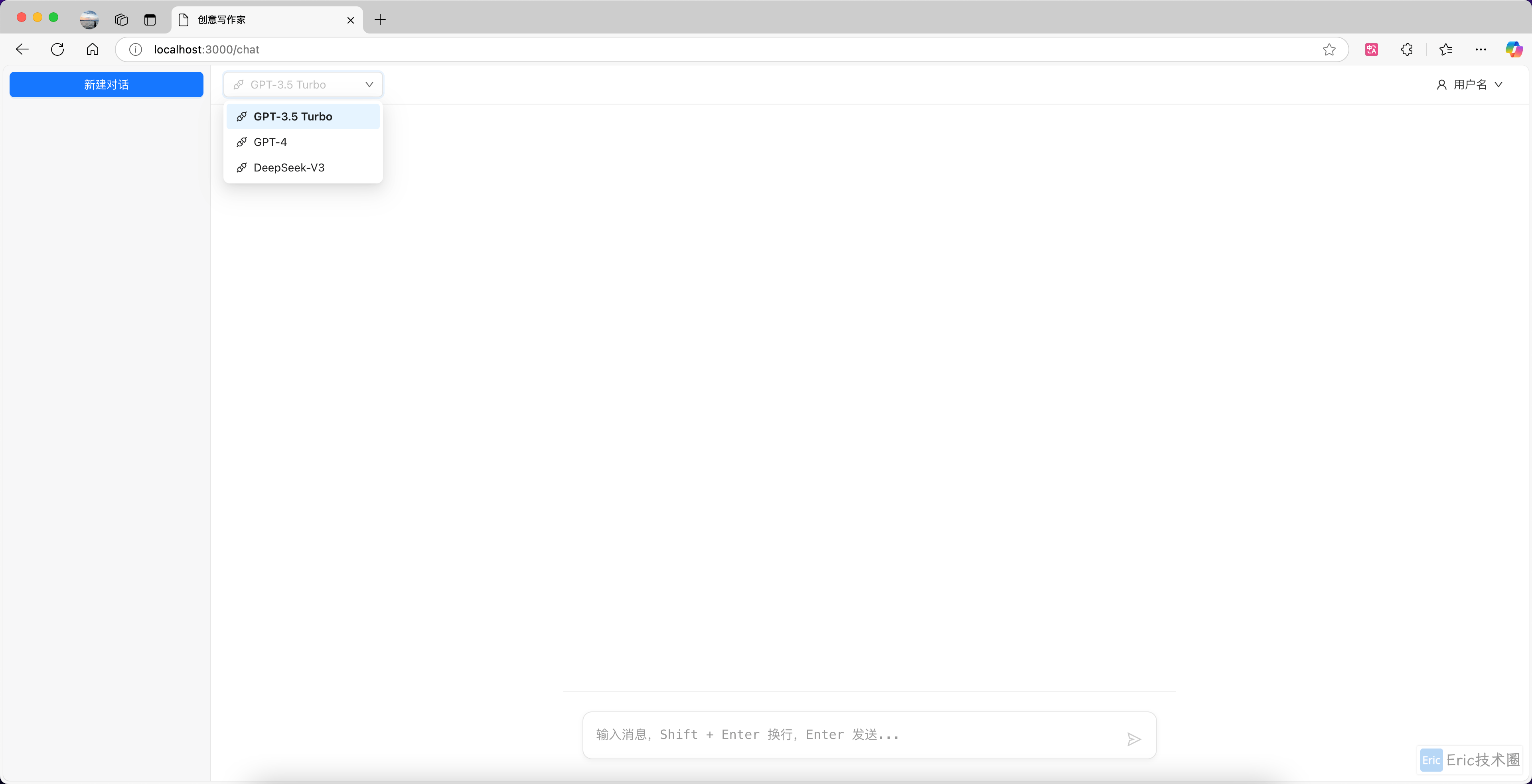
gpt 3.5:
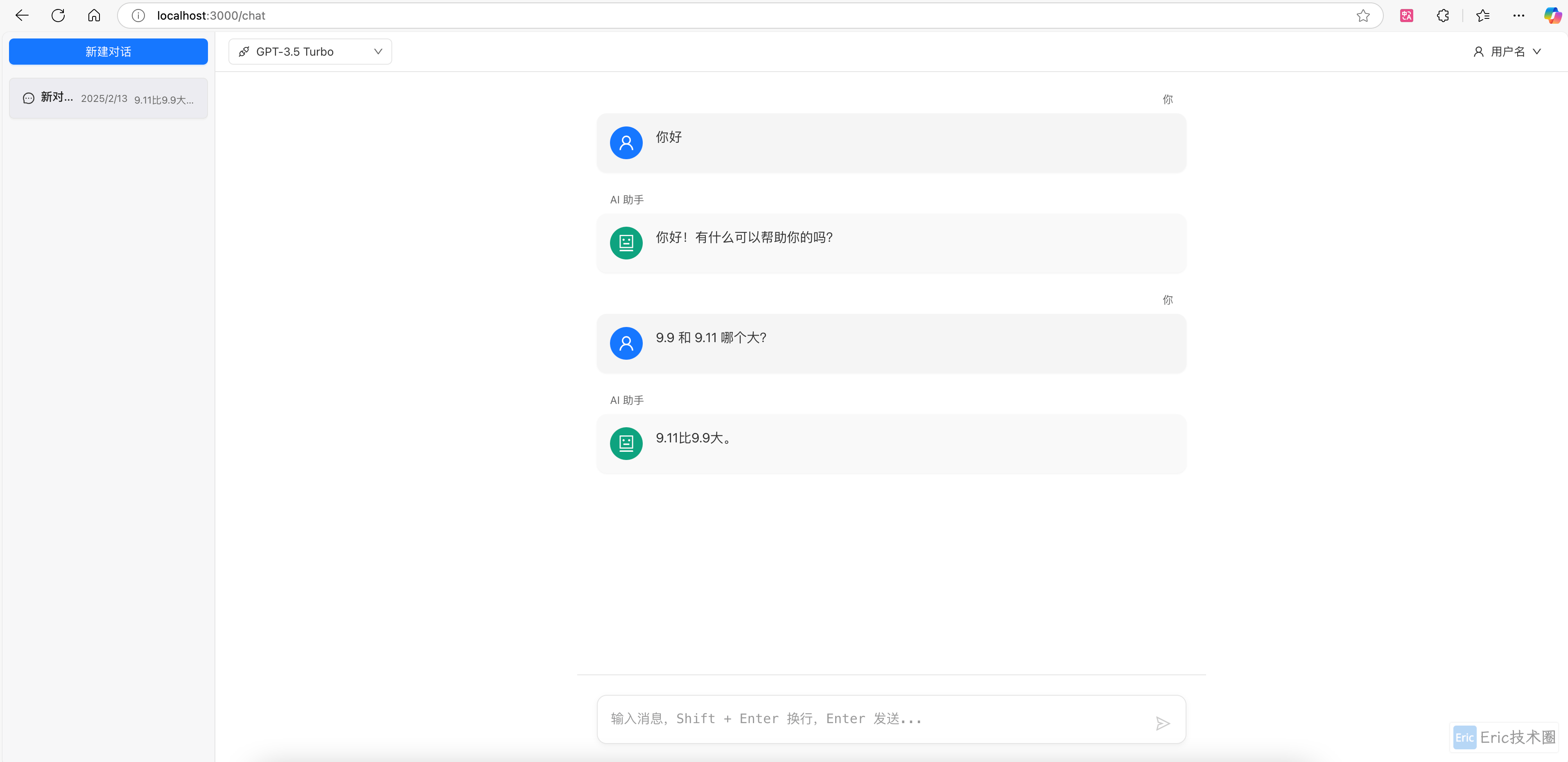
gpt-4:
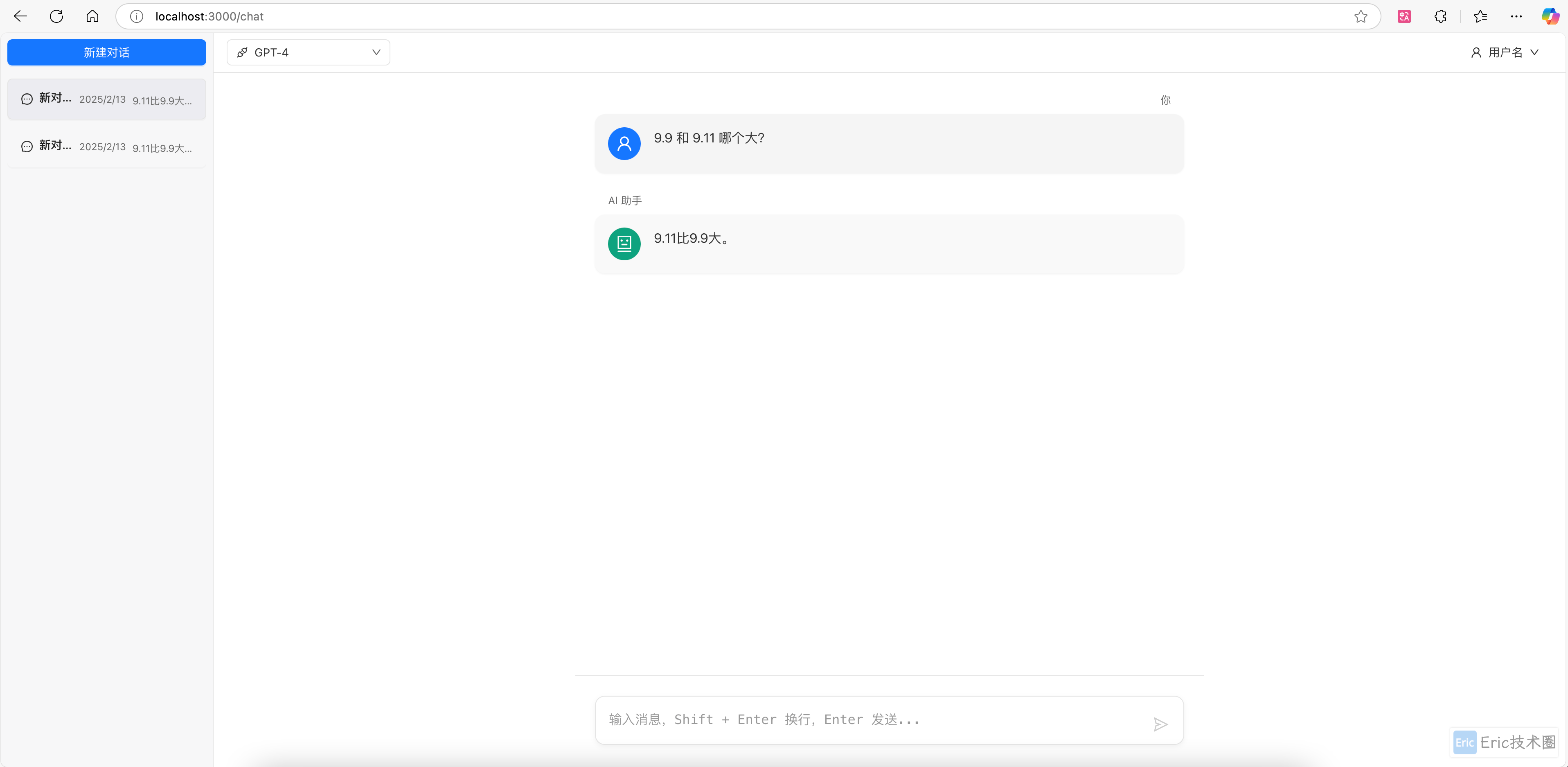
DeepSeek-v3:
最后
总体体验下来,Cline 有如下优点:
支持多种API提供商,如:OpenAI、DeepSeek、Google Gemini、Anthropic Claude、Alibaba Qwen、Ollama等。
类似于 Cursor,代码修改过程完全可视化,可以看到 AI 的每一步操作,甚至可以完全授权,代码不需要人工干预自动修改。
可以处理复杂的开发任务,从项目创建到文件编辑,再到终端命令执行,几乎覆盖所有的开发流程。
在生成错误的代码会自动修正,例如:生成的 TypeScript 语法错误,缺少依赖包等。
完全可以先免费体验,同时加上 DeepSeek,推理能力真的上了一个台阶。
但也有一些缺点:
处理复杂任务时,响应时间较长,这点尤其收到选择的 API 供应商,这点确实没法和 Cursor Fast 响应额度比。
Token 消耗速度太快了,简单任务会好很多。例如,百炼提供的免费 100 万额度不到两小时就消耗殆尽。
当你知道问题出在哪个文件,直接指定文件说明问题进行修改的时,效率较高,但有时 Cline 也会通过上下文修改其他文件,这时查找效率会比较低,甚至会去比对代码,但是又没有进行任何修改,这时就感觉傻傻的......
如果响应速度再提升 10 倍,token 再便宜些,模型的推理能力再强一些,其实这也是一种趋势了,未来可期。
欢迎关注我的公众号“Eric技术圈”,原创技术文章第一时间推送。