Alibaba COLA 4.0 架构实践
见字如面,与大家分享实践中的经验与思考。
复杂互联网业务项目普遍存在如下问题:
虽然整体架构规划做的不错,但落地严重偏离,缺乏足够的抽象和弹性设计,面向流程编程。
项目的工期紧、迭代快,导致代码结构混乱,几乎没有代码注释和文档,即使有项目代码规范。
项目代码规范冗长且繁杂,开发没有意愿去遵守。
多人协作开发,每个人的编码习惯不同,工具类代码各用个的,业务命名也经常冲突,团队成员庞大后更加影响效率。
项目Onbarding材料缺失、项目知识沉淀不足,在出现人员变动频繁的时候,新人根本没时间吃透代码结构,也很难快速了解上下文,紧迫的工期又只能让屎山越堆越大。
看似相同的功能,却很难加入改动,却经常听到:要写这张卡,先把之前的哪哪改了。
Code Review效果不佳,很难快速了解别人的上下文,只能简单看到一些命名、设计原则或明显的实现问题。
大部分团队几乎没有时间做代码重构,任由代码腐烂。或者没有动力或KPI进行代码重构。
不写单元测试,或编写的大量单元测试用处不大,有新功能加入或重构时导致要修改大量的测试。
随着时间的推移,代码就变得越来越腐败不堪,技术债务越来越庞大… 通过设计一个良好的应用分层架构,团队统一遵守一致的开发原则,风格保持一致,简单设计和实现,让代码的腐烂来得慢一些。(当然很难做到完全不腐烂)
应用架构的本质
架构的本质(要素结构):
要素 是 组成架构的重要元素;
结构 是 要素之间的关系。
而 应用架构的意义 就在于
定义一套良好的结构;
治理应用复杂度,降低系统熵值;
从随心所欲的混乱状态,走向井井有条的有序状态。

COLA架构就是为此而生,其核心职责就是定义良好的应用结构,提供最佳应用架构的最佳实践。通过不断探索,我们发现良好的分层结构,良好的包结构定义,可以帮助我们治理混乱不堪的业务应用系统。

经过多次迭代,定义出了相对稳定、可靠的应用架构:COLA v4。
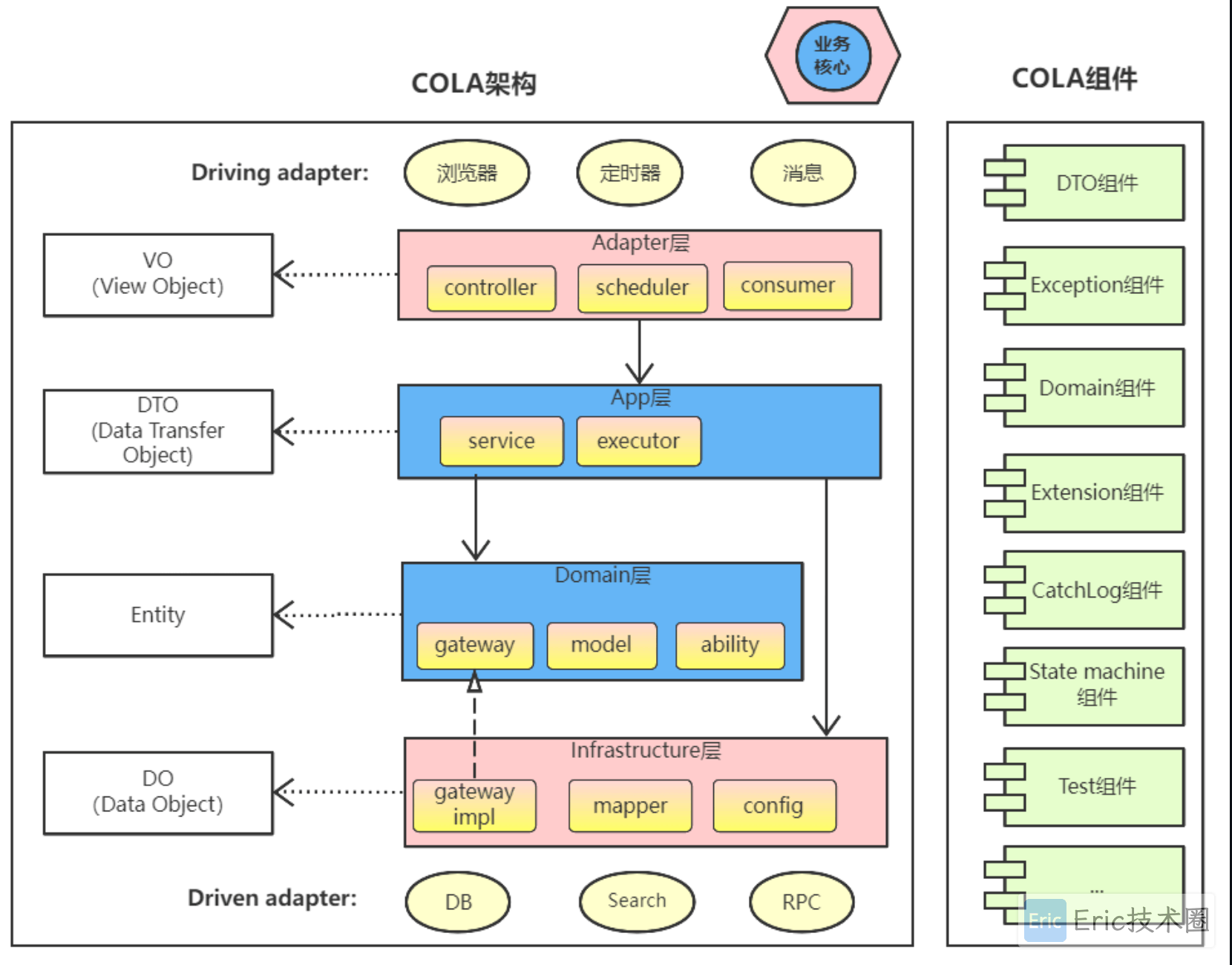
COLA 架构
COLA 概述
COLA 是 Clean Object-Oriented and Layered Architecture的缩写,代表“整洁面向对象分层架构”。 目前COLA已经发展到COLA v4。
COLA的官方博文中是这么介绍的:
自从COLA诞生以来,已经被使用在很多的业务系统里面,有CRM的业务,有电商的业务,有物流的业务,有外卖业务,有排课系统… COLA作为应用架构,有一定的普适性,是因为业务问题都有一定的共性。例如,典型的业务系统都需要:
接收request,响应response; 做业务逻辑处理,像校验参数,状态流转,业务计算等等; 和外部系统有联动,像数据库,微服务,搜索引擎等; 正是有这样的共性存在,才会有很多普适的架构思想出现,比如分层架构、六边形架构、洋葱圈架构、整洁架构(Clean Architecture)、DDD架构等等。
这些应用架构思想虽然很好,但我们很多同学还是“不讲Co德,明白了很多道理,可还是过不好这一生”。问题就在于缺乏实践和指导。COLA的意义就在于,他不仅是思想,还提供了可落地的实践。应该是为数不多的应用架构层面的开源软件。
COLA架构 区别于这些架构的地方,在于除了思想之外,我们还提供了可落地的工具和实践指导。
COLA分层
官方分层图:
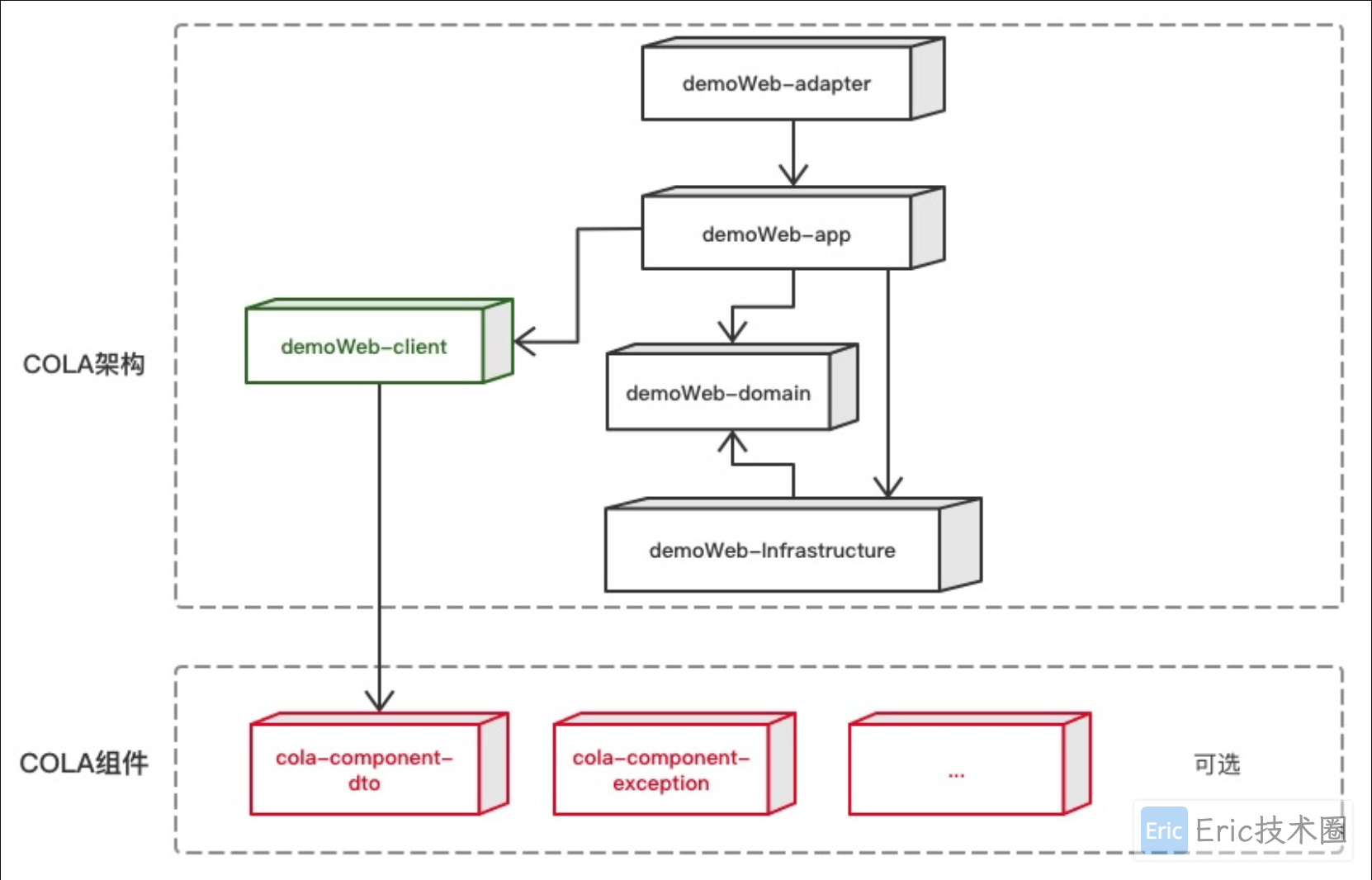
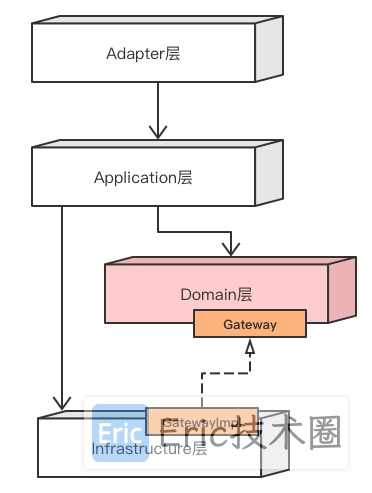
官方介绍的各层的命名和含义:
注意:这里做了一些改动,在domain和infra层,新增了repository来访问数据库,不与gateway网关耦合在一起。model 也不是必须的,因为 COLA 分层架构不是 DDD 架构。
COLA组件
大部分组件比较简单,企业内部可以进行简单的二次封装和改进。
Web Demo
项目初始化
mvn archetype:generate \
-DgroupId=top.flyeric \
-DartifactId=Eric-Cola-Demo \
-Dversion=1.0.0-SNAPSHOT \
-Dpackage=top.flyeric.demo \
-DarchetypeArtifactId=cola-framework-archetype-web \
-DarchetypeGroupId=com.alibaba.cola \
-DarchetypeVersion=4.3.2Parent Pom
<modules>
<module>Eric-Cola-Demo-client</module>
<module>Eric-Cola-Demo-adapter</module>
<module>Eric-Cola-Demo-app</module>
<module>Eric-Cola-Demo-domain</module>
<module>Eric-Cola-Demo-infrastructure</module>
<module>start</module>
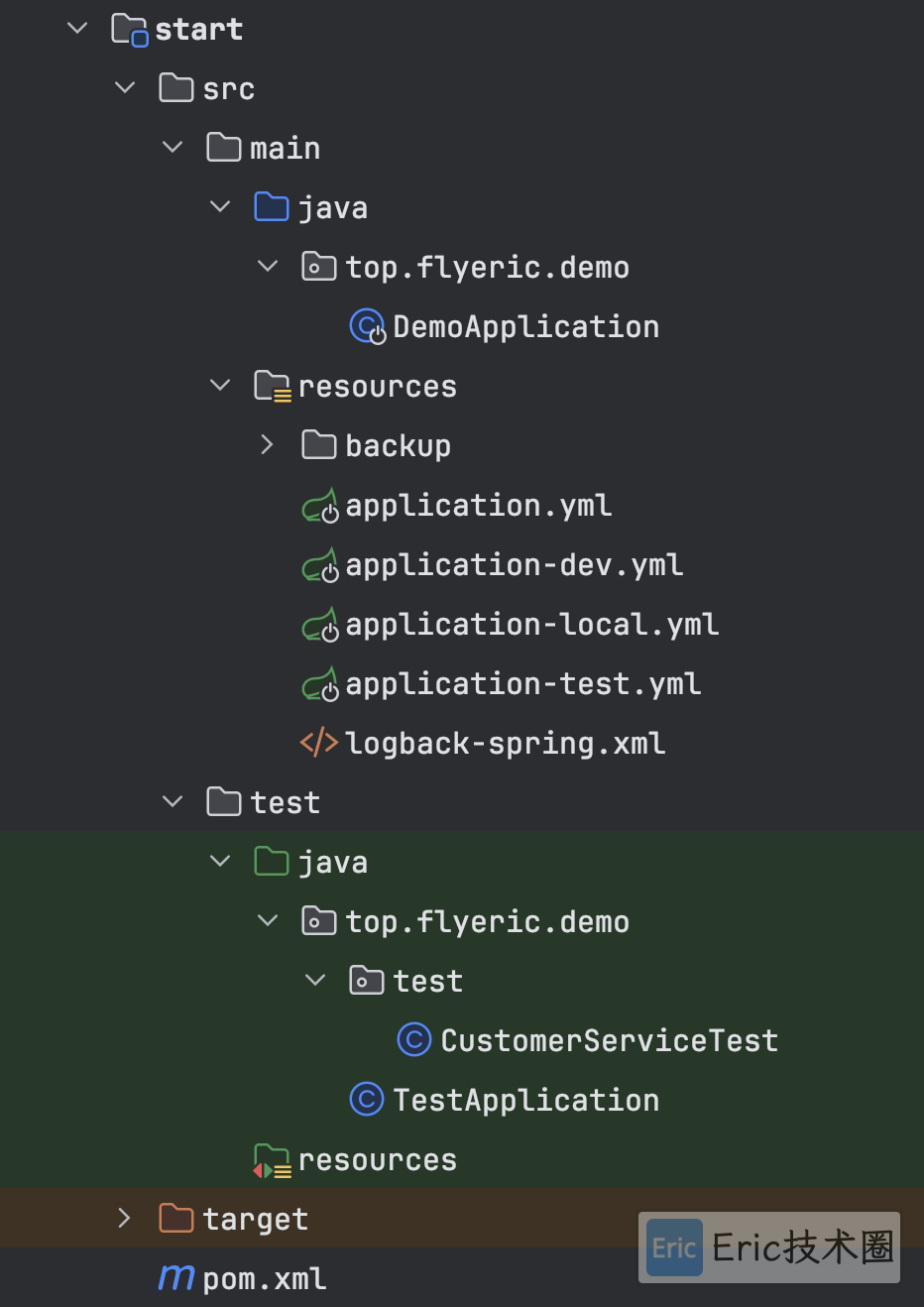
</modules>Start 层
作为整个应用的启动模块,只承担启动项目和全局相关配置项的存放职责。
代码结构如下:
Adapter 层
作为外部不同端的适配层,例如:Mobile(APP)、Wap(H5)、Web(PC Web)等不同的客户端的支持。
代码结构如下:

Client 层
定义 Service 服务层的接口,可以打包成 client SDK,提供给其他上游系统进行调用。
代码结构如下:
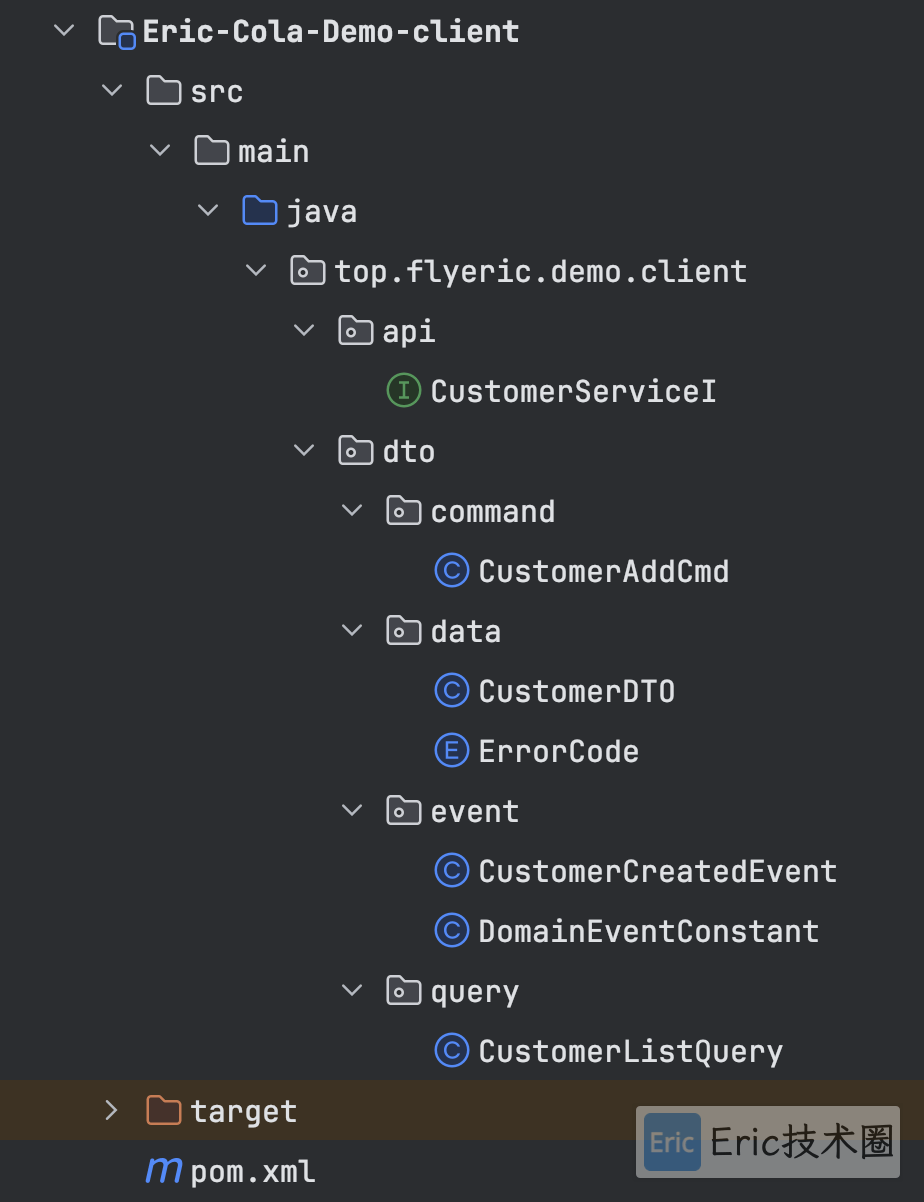
从上图中可以看到,client包里有:
api文件夹:存放服务接口定义
dto文件夹:存放传输实体
这里只是服务接口定义,而不是服务层的具体实现,所以在adapter层中,调用的其实是client层的接口:
@RestController
public class CustomerController {
private final CustomerServiceI customerService;
public CustomerController(CustomerServiceI customerService) {
this.customerService = customerService;
}
@GetMapping("/customer/page")
public PageResponse<CustomerDTO> pageCustomers(
@RequestParam(required = false, value = "customerId") String customerId,
@RequestParam(required = false, value = "companyName") String companyName
) {
CustomerListQuery customerListQry = new CustomerListQuery();
customerListQry.setCustomerId(customerId);
customerListQry.setCompanyName(companyName);
return customerService.pageCustomers(customerListQry);
}
}而具体实现逻辑放到了app层。
@Service("customerServiceImpl")
@CatchAndLog
public class CustomerServiceImpl implements CustomerServiceI {
@Resource
private CustomerCmdExecutor customerCmdExecutor;
@Resource
private CustomerQueryExecutor customerQueryExecutor;
public Response addCustomer(CustomerAddCmd customerAddCmd) {
return customerCmdExecutor.execute(customerAddCmd);
}
@Override
public MultiResponse<CustomerDTO> list(CustomerListQuery customerListQry) {
return customerQueryExecutor.listCustomers(customerListQry);
}
@Override
public PageResponse<CustomerDTO> pageCustomers(CustomerListQuery customerListQry) {
return customerQueryExecutor.doPageQuery(1, 10, () -> customerQueryExecutor.listCustomers(customerListQry));
}
}app 层
用于编排业务逻辑的实现,并且严格按照业务分包,这里划重点,是先按照业务分包,再按照功能分包的。
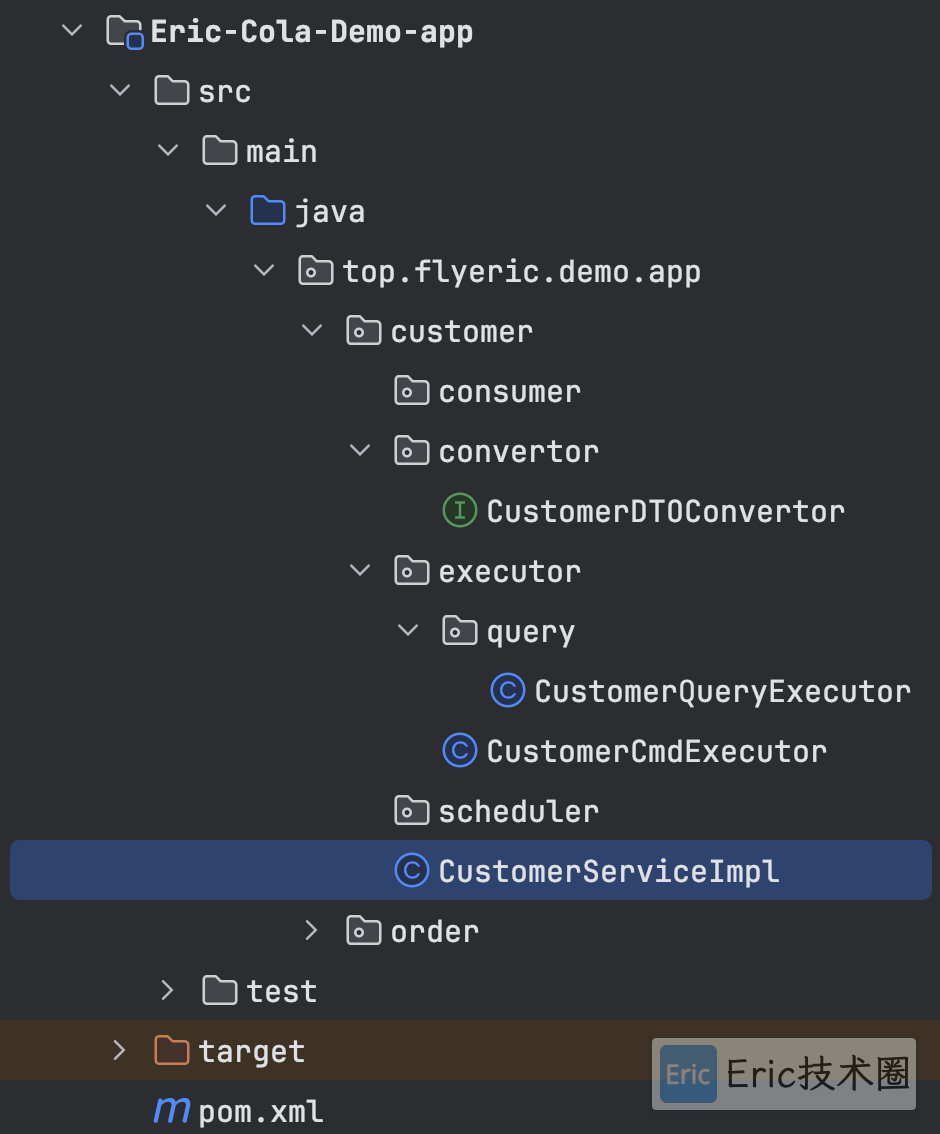
customer和order分别对应了消费着和订单两个业务子领域。里面是COLA定义app层下面三种功能:
可以看到,消息队列的消费者和定时任务,这类平时我们业务开发经常会遇到的场景,也放在app层。同时做了些微调,加入了convertor。
Domain层
代码结构如下:

也是按照不同的领域(customer和order)分包,里面则是4种主要的文件类型:
领域实体
使用充血模型,例如 Customer.java :
// Domain Entity can choose to extend the domain model which is used for DTO
@Data
public class Customer {
private String customerId;
private String memberId;
private String globalId;
private long registeredCapital;
private String companyName;
private SourceType sourceType;
private CompanyType companyType;
public Customer() {
}
public boolean isBigCompany() {
return registeredCapital > 10000000; //注册资金大于1000万的是大企业
}
public boolean isSME() {
return registeredCapital > 10000 && registeredCapital < 1000000; //注册资金大于10万小于100万的为中小企业
}
public void checkConflict() {
//Per different biz, the check policy could be different, if so, use ExtensionPoint
if ("ConflictCompanyName".equals(this.companyName)) {
throw new BizException(this.companyName + " has already existed, you can not add it");
}
}
}领域能力
在domainservice文件夹下,为了提供业务模型的领域能力,如上图中的CreditChecker
领域网关
gateway文件夹下的定义外部系统接口,实现交给infrastructure层去实现。
领域数据库访问
repository文件夹下的接口定义,同`gateway,也是交给infrastructure层去实现的接口。
例如
CustomerRepository里定义了接口queryByExample,要求infrastructure的实现类必须定义如何通过多请求参数获取Customer实体信息,而infrastructure层可以实现任何数据源逻辑,比如,从MySQL获取,从Redis获取,还是从外部API获取等等。
public interface CustomerRepository {
List<Customer> queryByExample(String customerId, String companyName);
}@Repository
public class CustomerRepositoryImpl implements CustomerRepository {
private final CustomerDOMapper customerMapper;
public CustomerRepositoryImpl(CustomerDOMapper customerMapper) {
this.customerMapper = customerMapper;
}
public List<Customer> queryByExample(String customerId, String companyName) {
CustomerDOExample customerDOExample = new CustomerDOExample();
if (StringUtils.isNoneBlank(customerId)) {
customerDOExample.or().andCustomerIdEqualTo(customerId);
}
if (StringUtils.isNoneBlank(companyName)) {
customerDOExample.or().andCompanyNameLike("%" + companyName + "%");
}
List<CustomerDO> customerDOList = customerMapper.selectByExample1(customerDOExample);
return customerDOList.stream().map(CustomerDOConvertor.CONVERTOR::toDomain).collect(Collectors.toList());
}
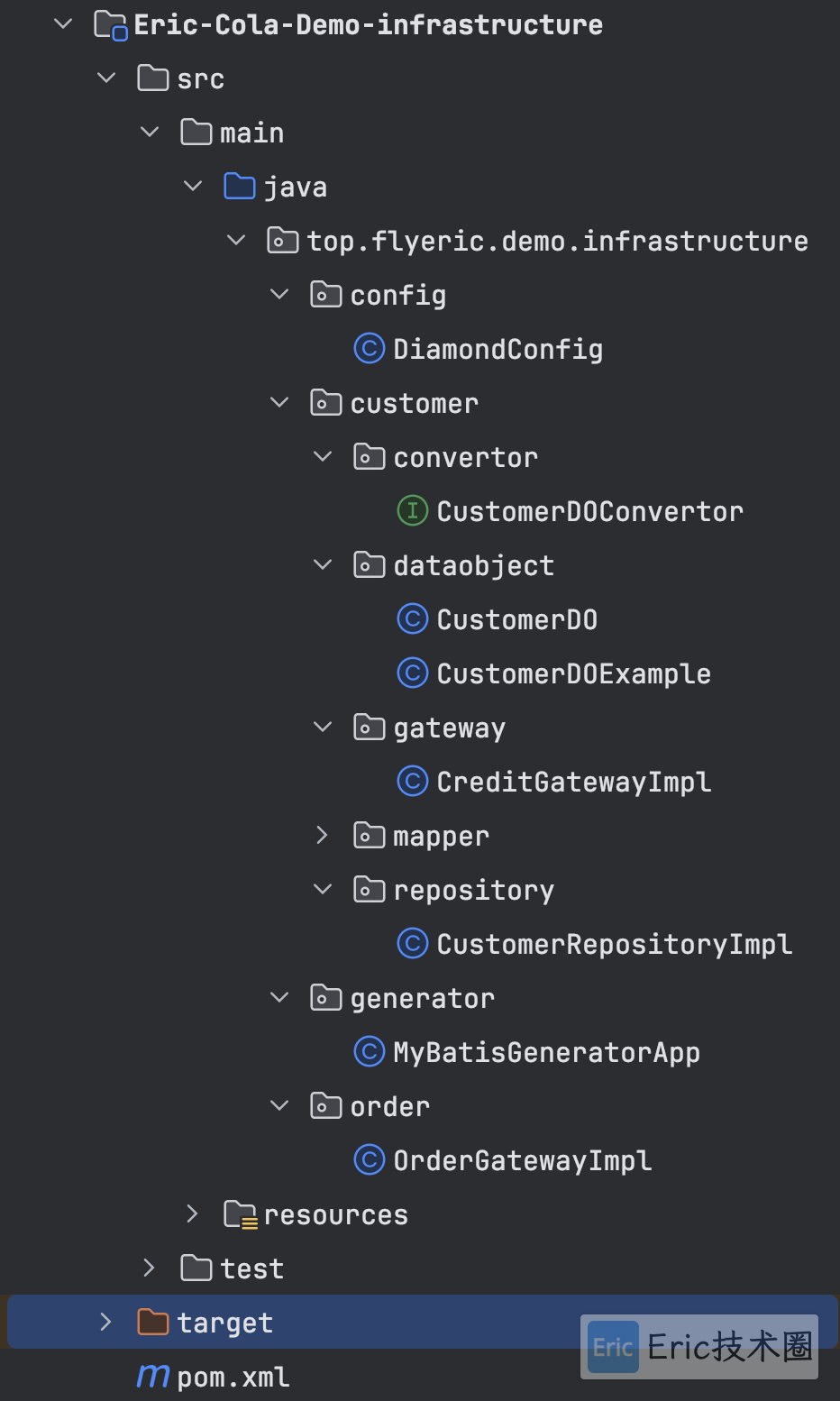
}Infrastructure层
infrastructure也就是基础设施层,主要有 repositoryimpl 、gatewayimpl的实现,也有MyBatis的mapper等数据源的映射和config配置文件。
最后,在引用一段官方介绍博客原文来总结COLA的层级:
适配层(Adapter Layer):负责对前端展示(web,wireless,wap)的路由和适配,对于传统B/S系统而言,adapter就相当于MVC中的controller;
应用层(Application Layer):主要负责获取输入,组装上下文,参数校验,调用领域层做业务处理,如果需要的话,发送消息通知等。层次是开放的,应用层也可以绕过领域层,直接访问基础实施层;
领域层(Domain Layer):主要是封装了核心业务逻辑,并通过领域服务(Domain Service)和领域对象(Domain Entity)的方法对App层提供业务实体和业务逻辑计算。领域是应用的核心,不依赖任何其他层次;
基础实施层(Infrastructure Layer):主要负责技术细节问题的处理,比如数据库的CRUD、搜索引擎、文件系统、分布式服务的RPC等。此外,领域防腐的重任也落在这里,外部依赖需要通过gateway的转义处理,才能被上面的App层和Domain层使用。
COLA 的特点
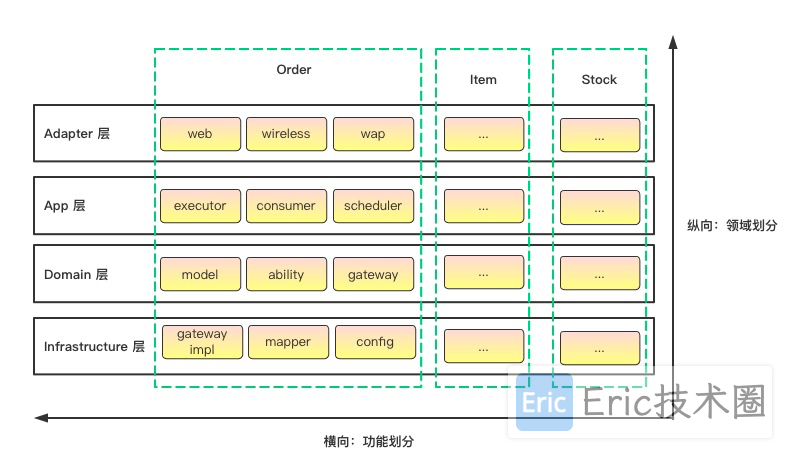
分包策略
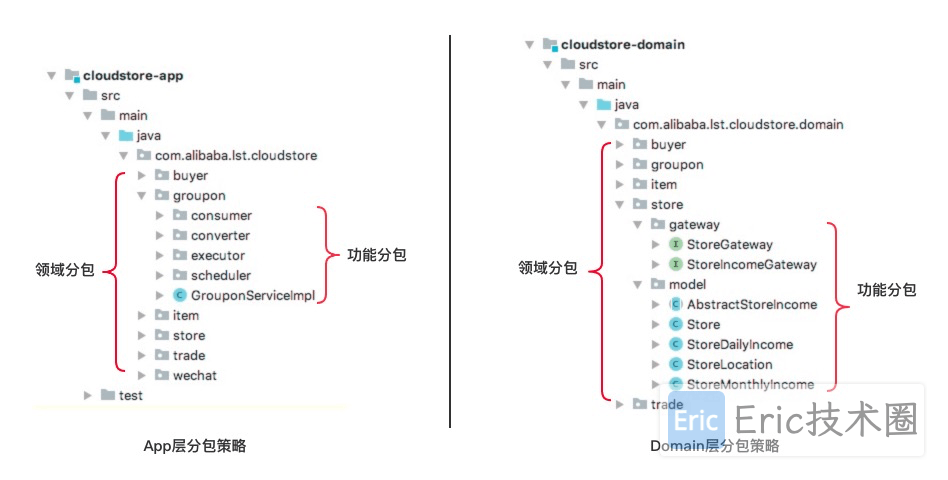
在每一个module下面首先按照领域做一个顶层划分,然后在领域内,再按照功能进行分包。例如:先按领域划分成 Order、Item和Stock,然后分别按照功能分包,如:consumer、executor、scheduler 等。
依赖解耦
“高内聚,低耦合”这句话,你工作的越久,就越会觉得其有道理。
所谓耦合就是联系的紧密程度,只要有依赖就会有耦合,不管是进程内的依赖,还是跨进程的RPC依赖,都会产生耦合。依赖不可消除,同样,耦合也不可避免。我们所能做的不是消除耦合,而是把耦合降低到可以接受的程度。在软件设计中,有大量的设计模式,设计原则都是为了解耦这一目的。
在DDD中有一个很棒的解耦设计思想——防腐层(Anti-Corruption),简单说,就是应用不要直接依赖外域的信息,要把外域的信息转换成自己领域上下文(Context)的实体再去使用,从而实现本域和外部依赖的解耦。
在COLA中,我们把AC这个概念进行了泛化,将数据库、搜索引擎等数据存储都列为外部依赖的范畴。利用依赖倒置,使用repository/gateway来实现业务领域和外部依赖的解耦。

总结
COLA架构并不复杂,COLA已经从1.0版本经过逐次精简,发展到了如今的形态。通过脚手架能够快速生成多module的maven项目,节省很多的项目启动搭建的时间。
参考文章
COLA 4.0:应用架构的最佳实践_cola4.0-CSDN博客
GitHub - alibaba/COLA: 🥤 COLA: Clean Object-oriented & Layered Architecture
欢迎关注我的公众号“Eric技术圈”,原创技术文章第一时间推送。