Qwen3-Coder-Flash 本地部署及编程体验
见字如面,与大家分享实践中的经验与思考。
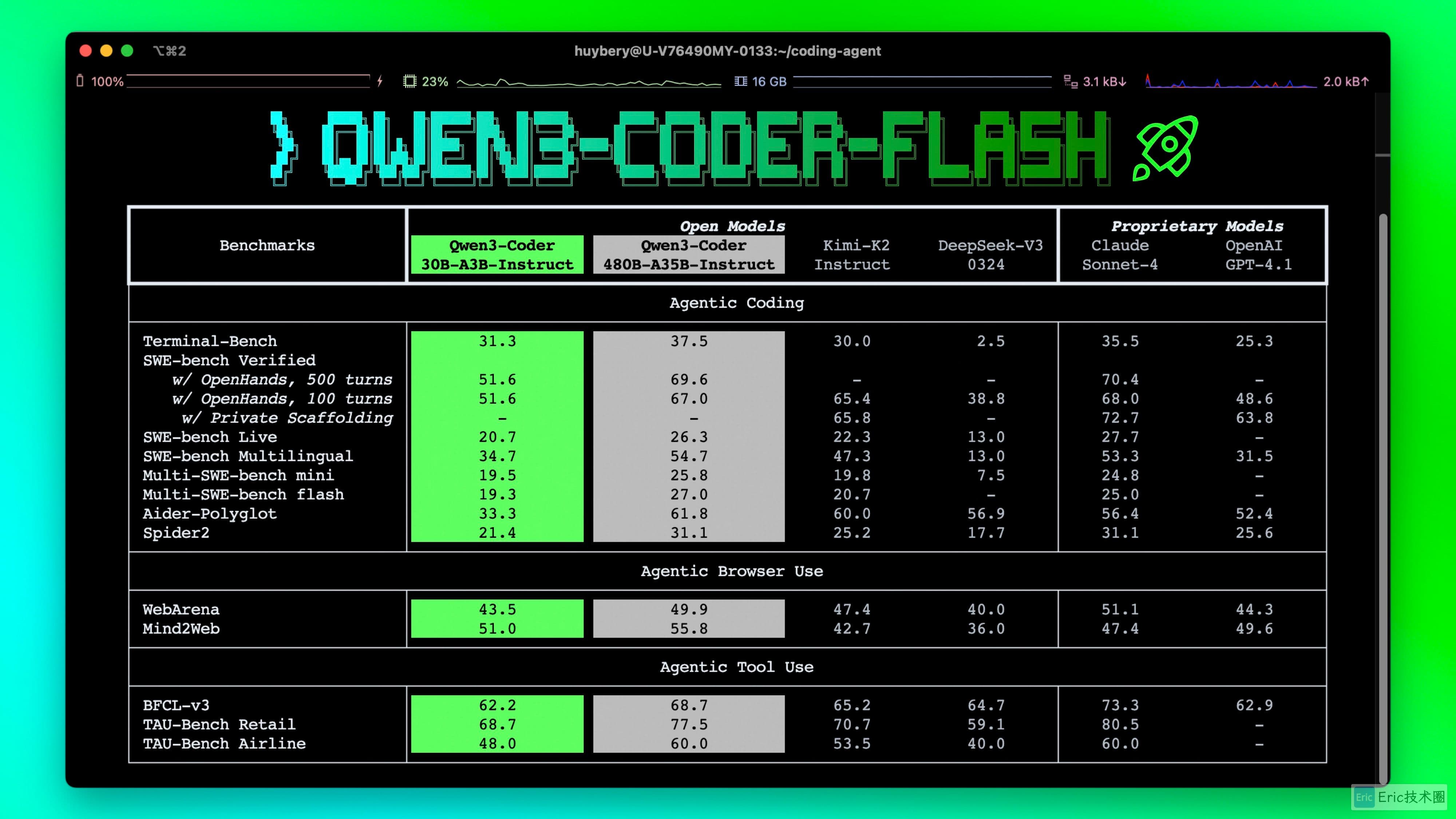
Qwen3-Coder 是阿里巴巴推出的专门针对代码生成和编程任务优化的大语言模型系列。其中,Qwen3-Coder-30B-A3B-Instruct 是该系列的精简模型,保持了出色的性能和效率,具有以下关键改进:
在 代理编码、代理浏览器使用 和其他基础编码任务上,在开放模型中表现出显著的性能。
具有原生支持 256K 令牌的 长上下文能力,并且可以使用 Yarn 扩展到 1M 令牌,优化了对仓库规模的理解。
代理编码 支持大多数平台,如 Qwen Code、CLINE,并具有特别设计的函数调用格式。
本地部署友好,支持在消费级硬件上进行本地部署,保护代码隐私。
本文将详细介绍如何在本地部署 Qwen3-Coder 模型,并通过部分简单案例展示其在前端开发中的应用效果。
本地部署方案
本文将介绍两种主流的本地部署方案:LM Studio 和 Ollama。两种方案各有特点,可以根据个人使用习惯和需求进行选择。
方案一:LM Studio 部署
LM Studio 是一个用户友好的 GUI 工具,特别适合新手用户进行模型管理和测试。
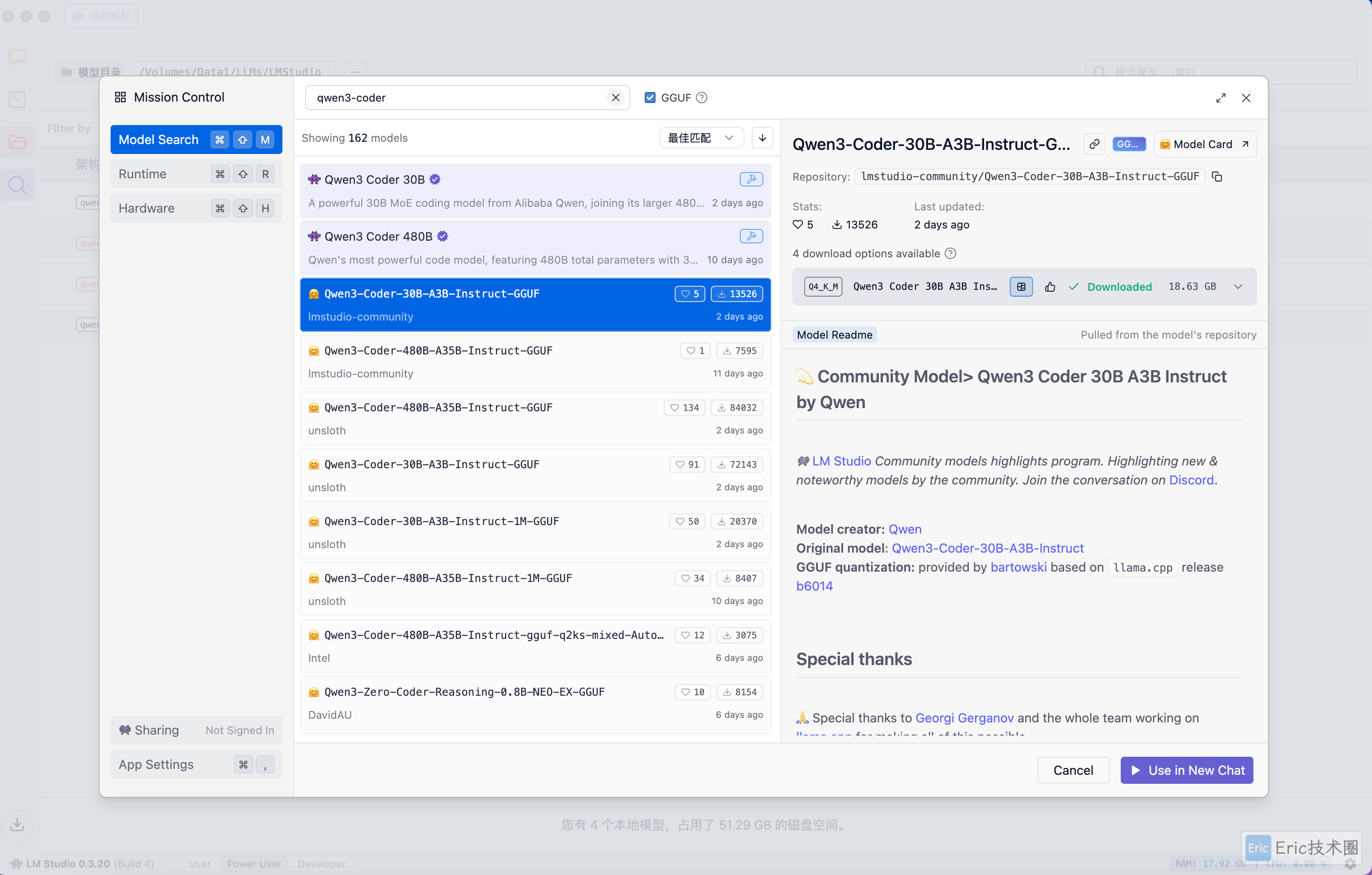
模型下载
首先在 LM Studio 中搜索并下载 Qwen3-Coder 模型:
功能测试
下载完成后,我们使用一个前端开发的测试用例来验证模型效果:
测试提示词:
你是一名前端开发专家,请用 HTML 和 CSS 开发一个从事软件开发行业的企业官网。运行效果:
性能指标:
显存占用:18GB,推理速度:16 tokens/s,整体表现:流畅稳定。
生成效果展示
模型生成的企业官网效果如下:
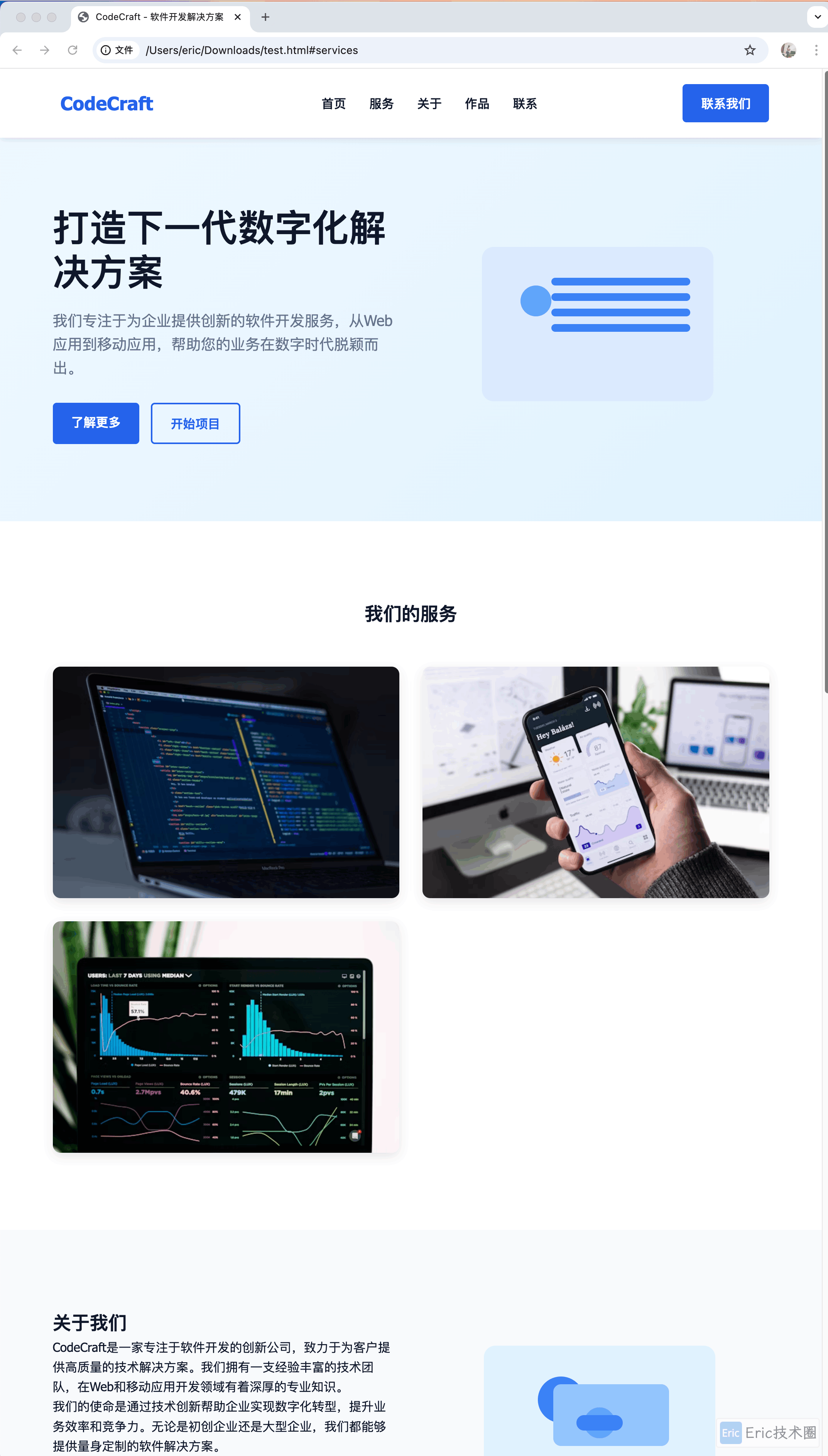
可以看到,生成的页面布局合理,样式美观,完全符合现代企业官网的设计标准。
方案二:Ollama 部署
Ollama 是一个命令行工具,更适合开发者进行模型管理和集成开发。最新版本支持 Chat 聊天界面,可以方便地在本地模型间切换。
模型安装
通过命令行快速安装 Qwen3-Coder 模型:
ollama run qwen3-coder:30b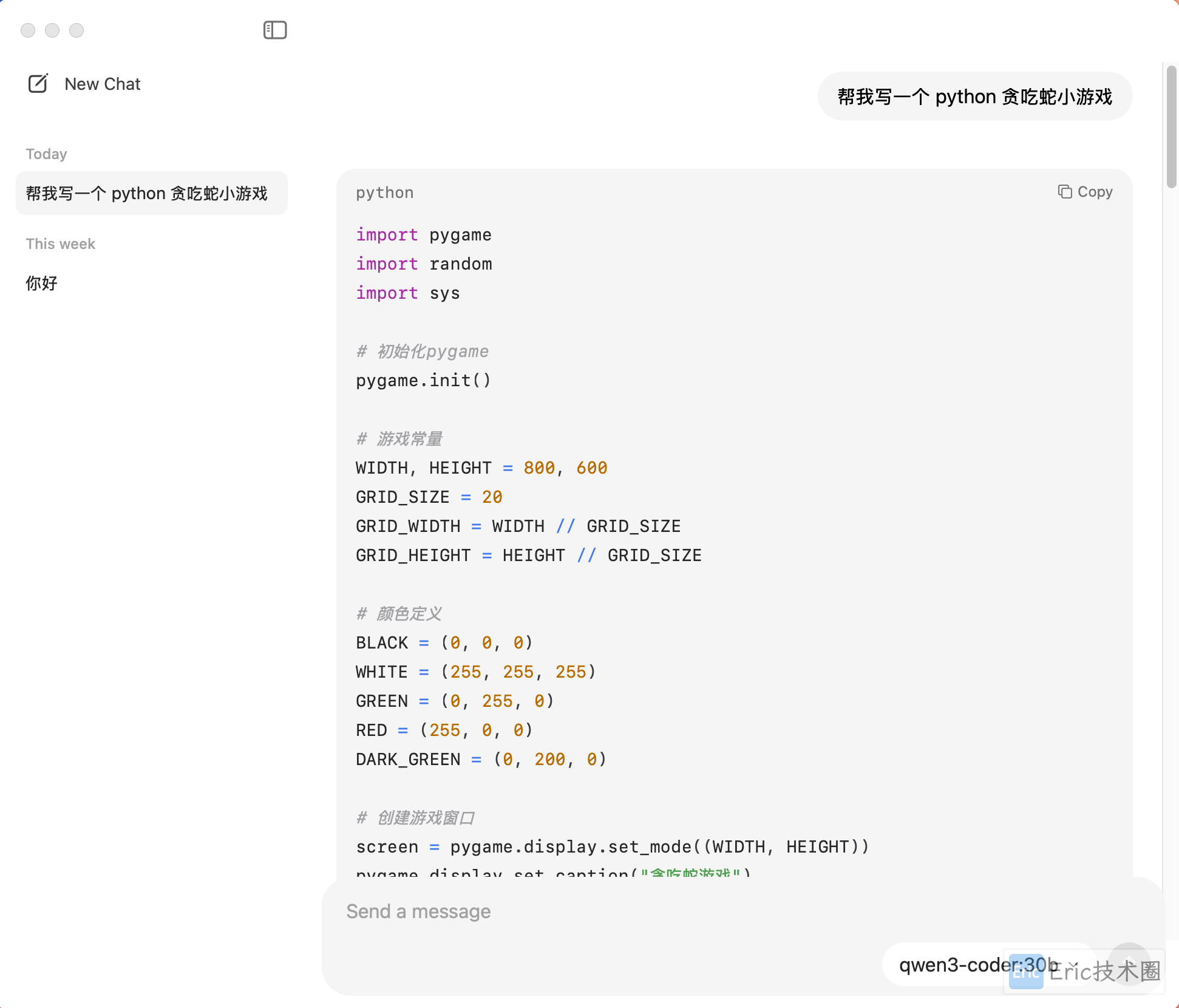
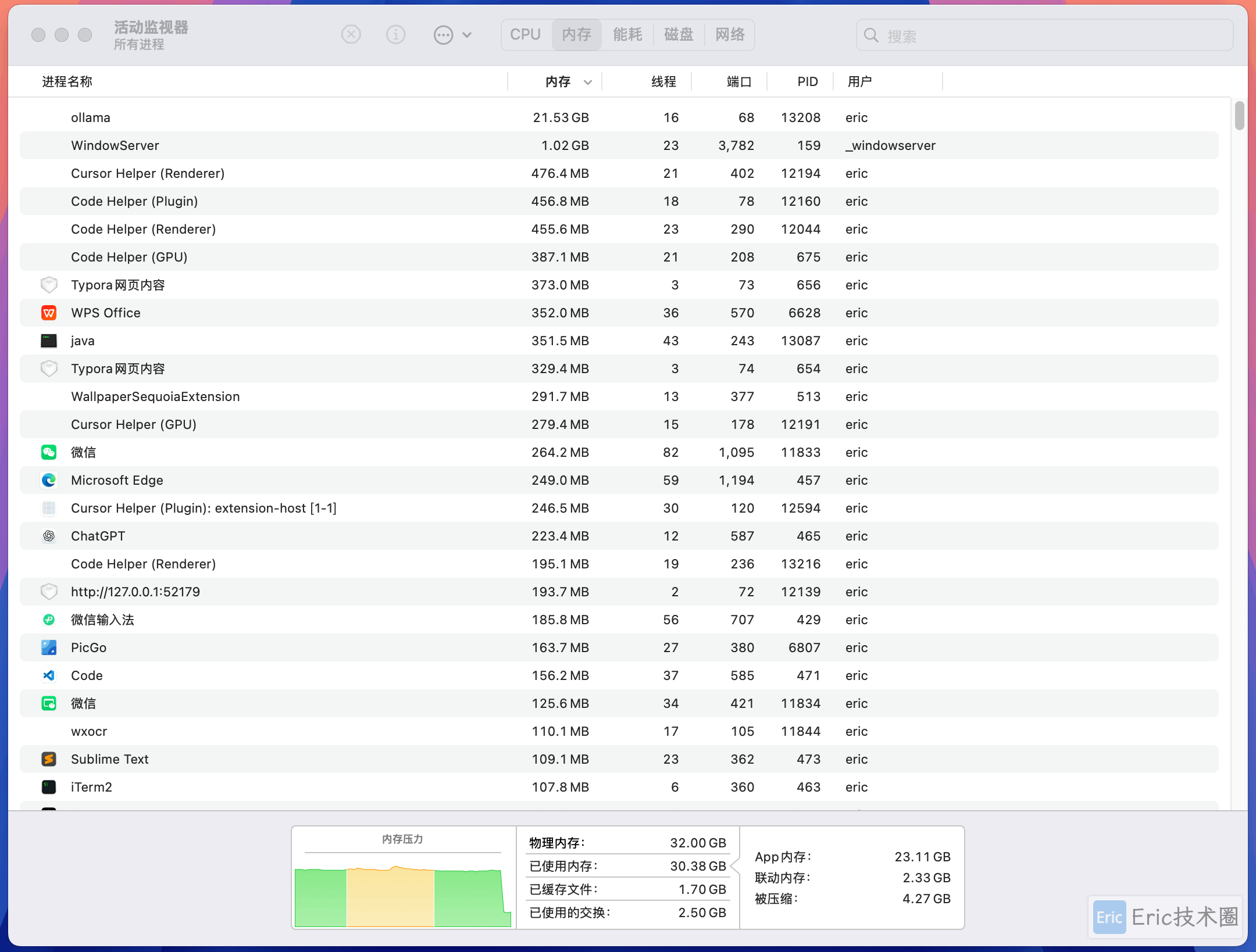
资源监控
运行期间的系统资源占用情况:
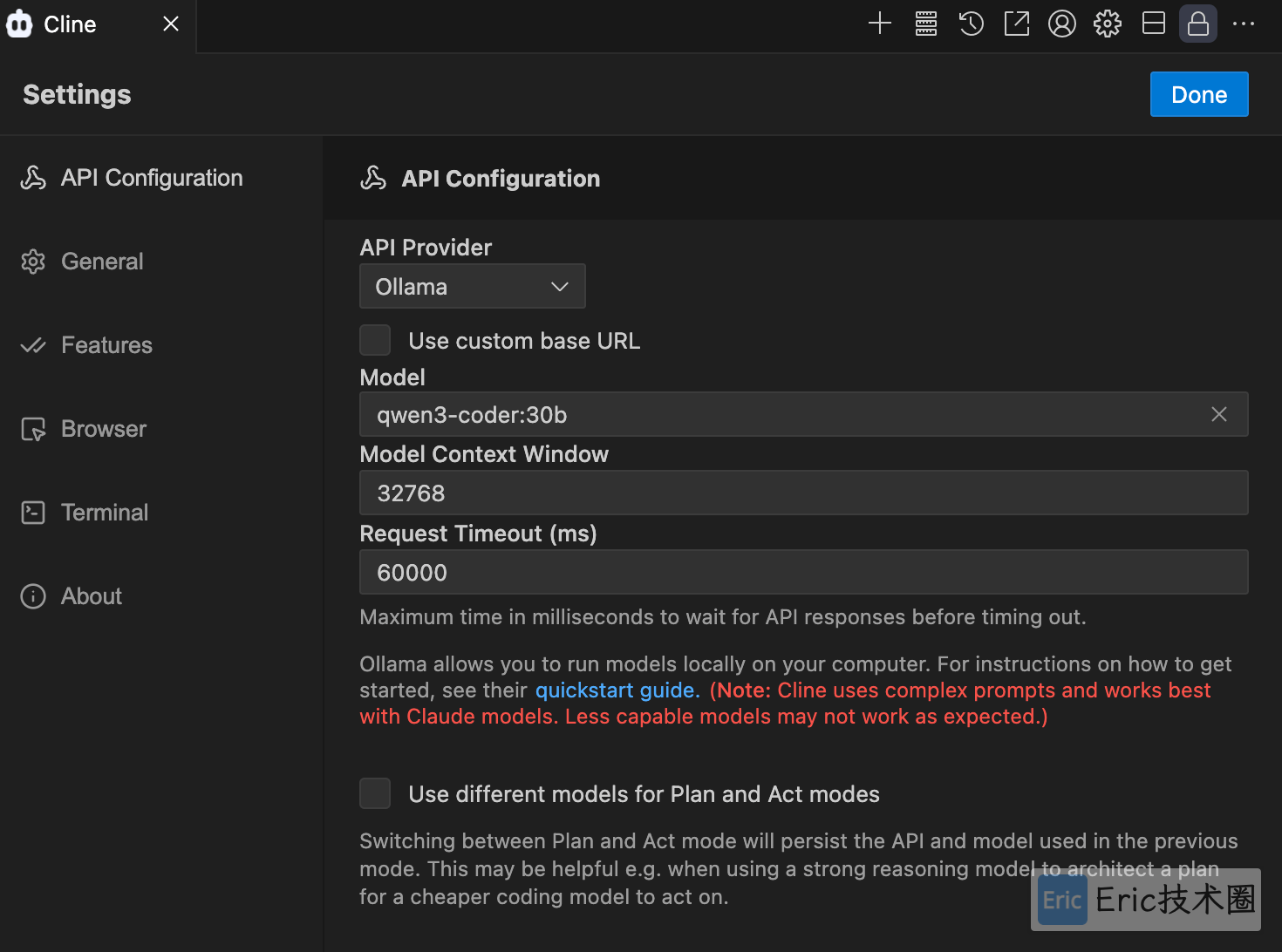
IDE 集成开发
Ollama 的一大优势是可以轻松集成到各种开发环境中。这里我们使用 VS Code + Cline 插件进行实战编程体验:
实战测试
我们使用更具体的提示词来测试模型的项目生成能力:
测试提示词:
你是一名资深的前端开发工程师,请使用 HTML 和内置 CSS 开发一个软件开发工作室的企业官网。请将文件统一放在 kimi-k2-demo 下的official-website2 目录下生成效果:
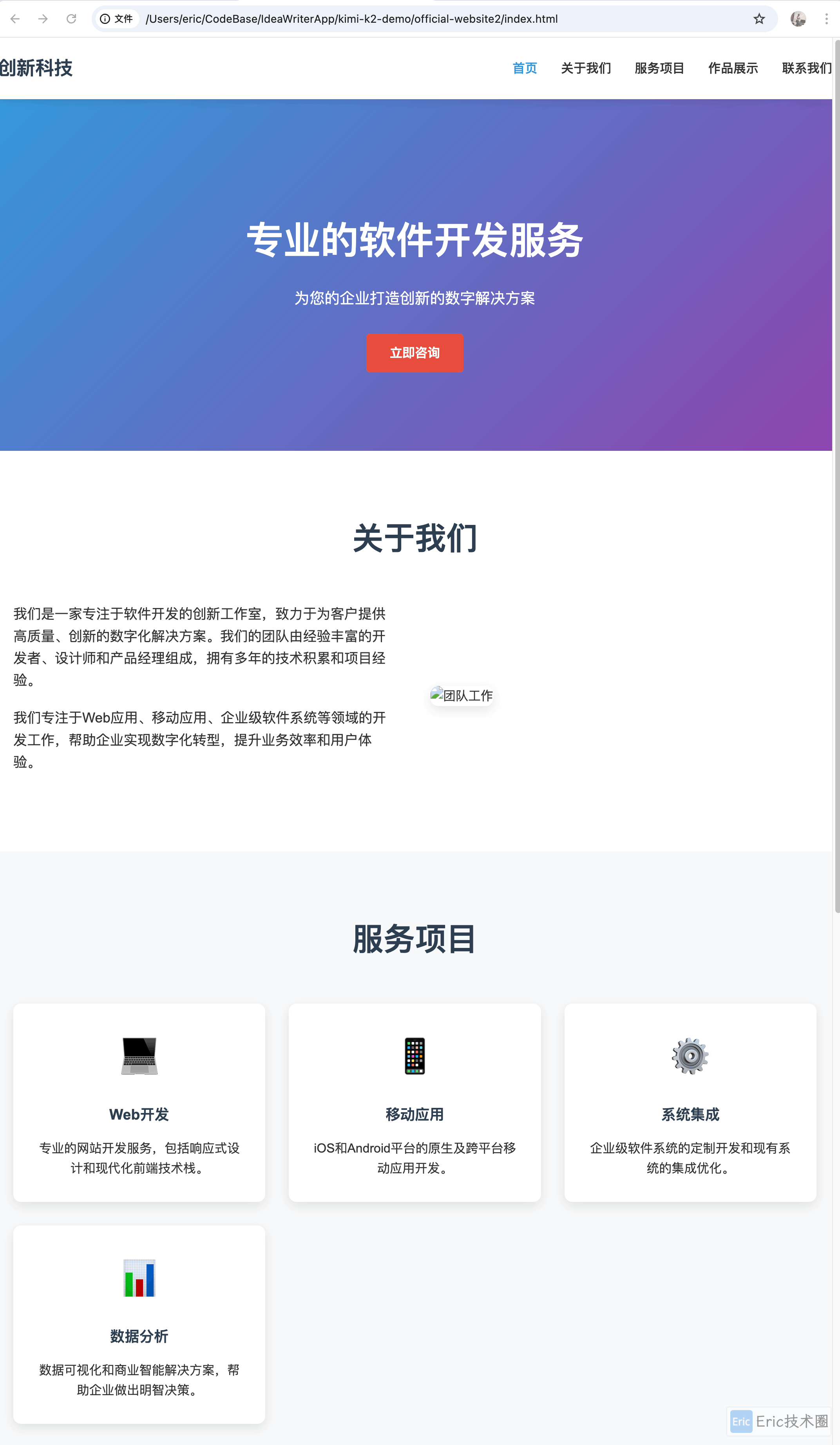
项目结构:
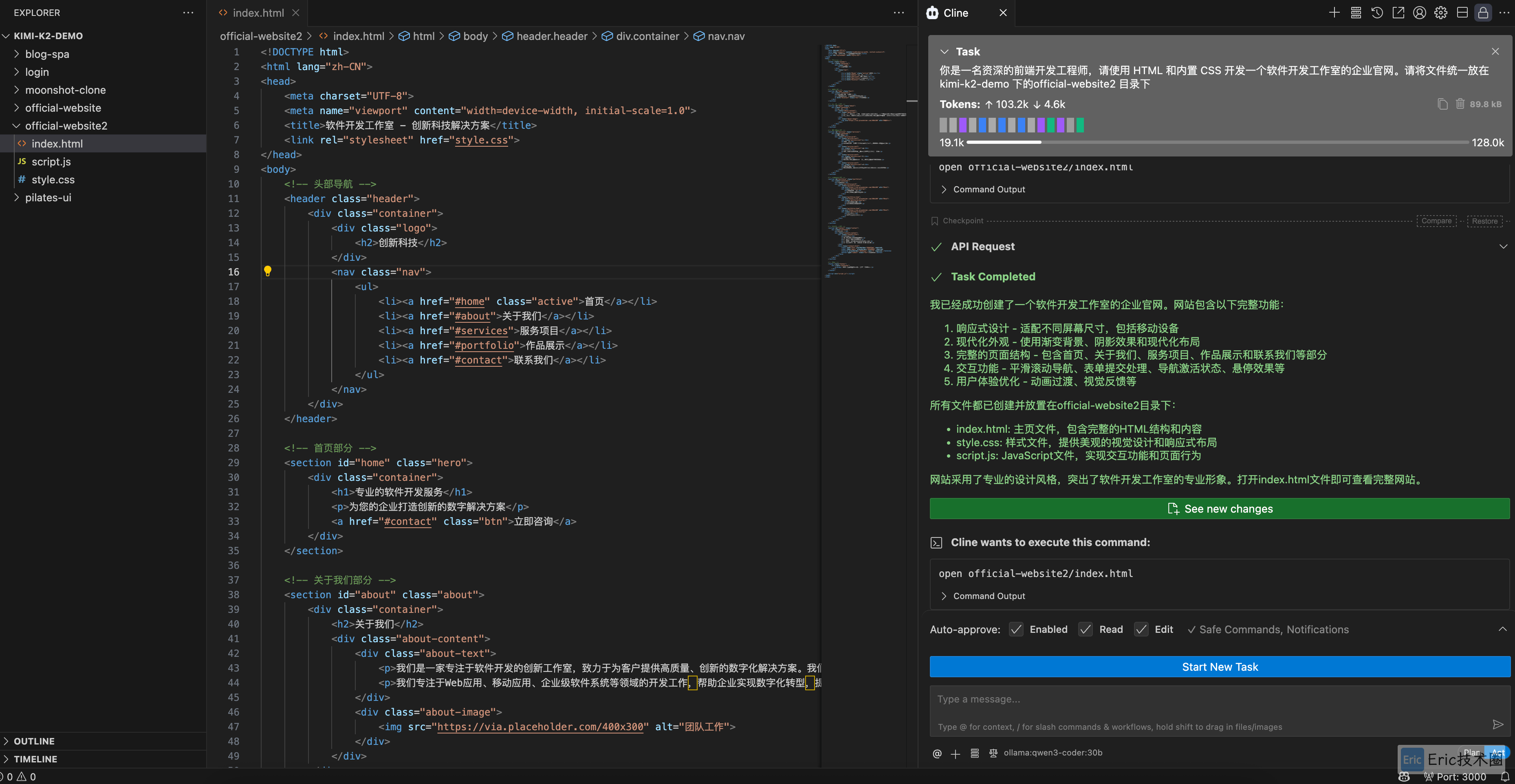
可以看到,模型不仅生成了完整的 HTML 和 CSS 代码,还按照要求创建了规范的项目目录结构,充分体现了其对项目组织的理解能力。
本地部署表现
通过实际测试,Qwen3-Coder-30B 模型在本地部署时的表现总结如下:
部署方案对比
硬件配置要求
显存需求:至少 18GB VRAM
内存需求:建议 32GB+ RAM
存储空间:模型文件约 20GB
性能指标
推理速度:16 tokens/s(在 32 GB 硬件配置下)
响应质量:代码生成准确度高,符合现代开发标准
上下文处理:在处理大型项目时需要更大的量化尺寸以及上下文
总结
Qwen3-Coder 作为专门优化的编程模型,在本地部署方面表现出色。虽然当前硬件限制了处理大型项目的能力,但对于日常的开发辅助和中小型项目来说,已经完全可以胜任。随着硬件性能的不断提升,本地 AI 编程助手将成为开发者工作流中不可或缺的一部分。
对于想要尝试本地 AI 编程的开发者,建议:
从简单的代码生成任务开始
根据自己的硬件配置选择合适的部署方案
逐步探索模型在具体开发场景中的应用潜力
欢迎关注公众号"Eric技术圈",原创技术文章第一时间推送。