推荐一个小白用户也能快速使用的本地 AI 知识库方案(附视频演示)
见字如面,分享实践中的经验与思考。若有启发,请点赞收藏。
之前出过一期关于本地 AI 知识库的文章《快速搭建本地大语言模型和知识库》,使用的是 Ollama 和 AnythingLLM。然而在实际使用过程中,我发现了几个明显的体验问题:
早期参数量较小的大语言模型能力有限,中文支持尤其欠佳
响应速度慢,影响使用体验
嵌入模型向量化效果不理想,基于知识库的回答质量不够满意
今天我将使用 Ollama + Cherry Studio + Qwen3 模型 + MCP 工具重新打造一套更优质的本地 AI 知识库方案。这套方案特别适合非程序员用户,上手快速,零成本即可使用。
下面提供完整的文字教程,如果想要观看视频演示,可以访问以下链接:
前期准备
简单了解 RAG
RAG(Retrieval-Augmented Generation)是一种结合了信息检索与生成模型的技术,通过先从外部知识库中检索相关内容,再由大语言模型生成回答,从而提升回答的准确性和上下文相关性。
下图直观展示了 RAG 的数据流转过程:
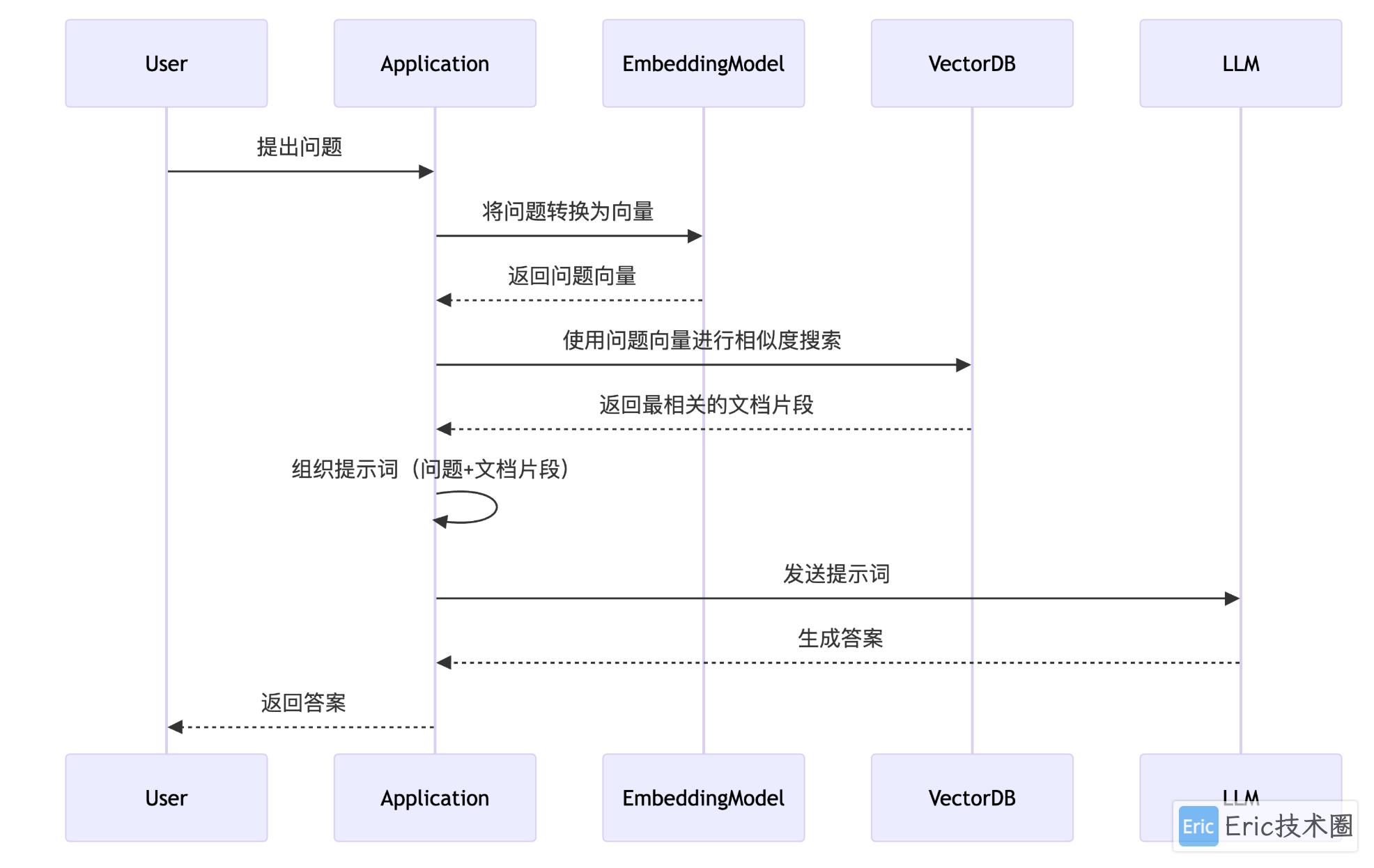
来源:https://github.com/CherryHQ/cherry-studio-docs/blob/main/knowledge-base/data.md
RAG 本地知识库的核心要素包括:
高质量知识库文档:用户需提供结构清晰、内容丰富的文档,这是有效信息支撑的基础
Embedding 嵌入模型:将文本内容分段转换为低维向量并存储到向量数据库中,支持语义相似性搜索(简单理解为"找到意思相近的内容")
Reranker 重排序模型:对初步筛选出的相似内容进行精确评分排序,提升检索结果的准确度(相当于"先用嵌入模型粗选,再用重排序模型精排")
大语言模型:作为系统的"大脑",负责理解检索到的相关内容,并生成连贯、准确的最终回答
大语言模型选择
大语言模型的选择至关重要。针对个人轻量级知识库场景,我推荐使用 qwen3-8b 作为本地知识库的大语言模型。虽然其参数量相对较低,但在实际应用中表现出色。根据海外社区 Reddit 的测试结果,qwen3-8b 在 RAG 应用方面得分相当不错:

来源:https://www.reddit.com/r/LocalLLaMA/comments/1kaqi3k/qwen_3_8b_14b_32b_30ba3b_235ba22b_tested/
使用 Ollama 下载 qwen3 和相应的嵌入模型后,可以在终端查看已安装的模型:
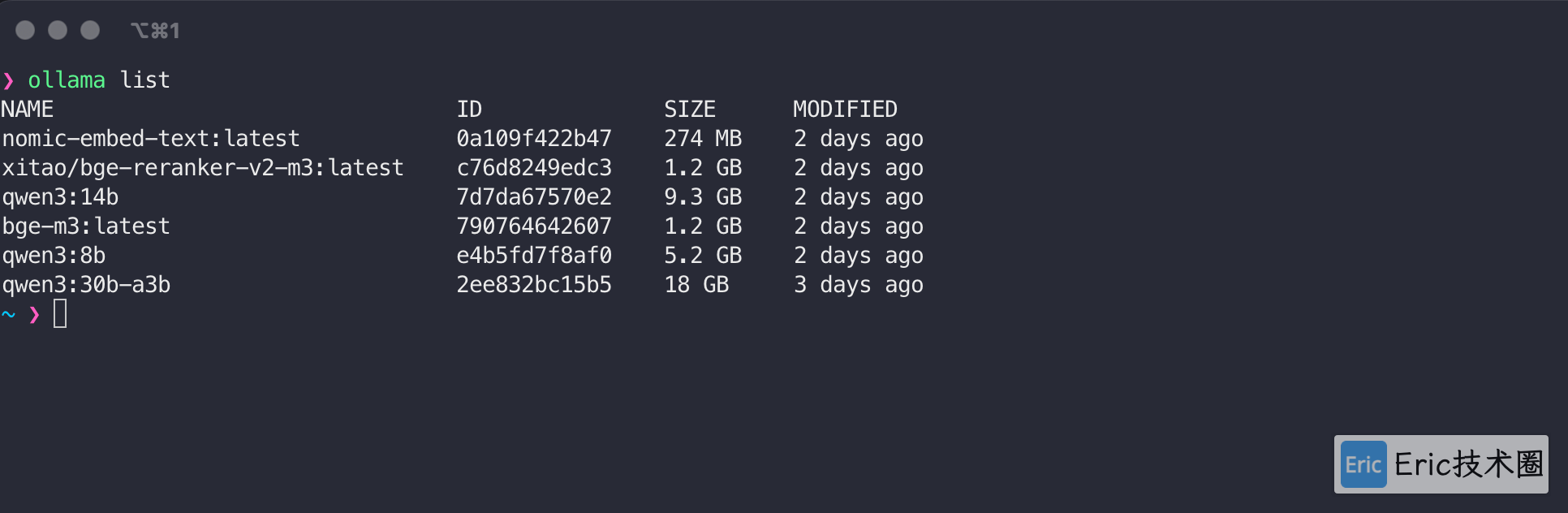
非程序员用户请注意:如果你不熟悉终端操作或不知道如何下载模型,可以直接跳过这一步,后续会有更简便的方法。
知识库文档准备
高质量的知识库文档是系统高效运行的关键。除了手动整理文档外,我们还可以借助 AI 从网络抓取高质量内容,并以 markdown 格式存储到本地(这种格式对 AI 处理特别友好)。
例如:可以添加一些常用的 MCP 工具(如 fetch、filesystem 等),从官网或其他渠道爬取内容并保存到本地。
以下是一个实用的提示词模板,只需替换你想要爬取的网页地址:
使用 sequential-thinking 工具思考并完成下面的工作:
使用 fetch 工具查询网址:https://docs.cursor.com/context/model-context-protocol,并获取网页正文中的每个链接的内容
使用 filesystem 工具将每个网页的内容保存为一个单独的 markdown 文件,保存在 docs 文件夹中
关于 MCP 的详细配置方法,可以参考 Cursor 101 系列视频的第 4 集《MCP 详解与配置》,本文不再赘述。
实操
现在让我们打开 Cherry Studio 应用,开始实际操作。
01 添加模型
首先需要在 Ollama 和硅基流动平台中分别添加推理模型、嵌入模型和重排模型:
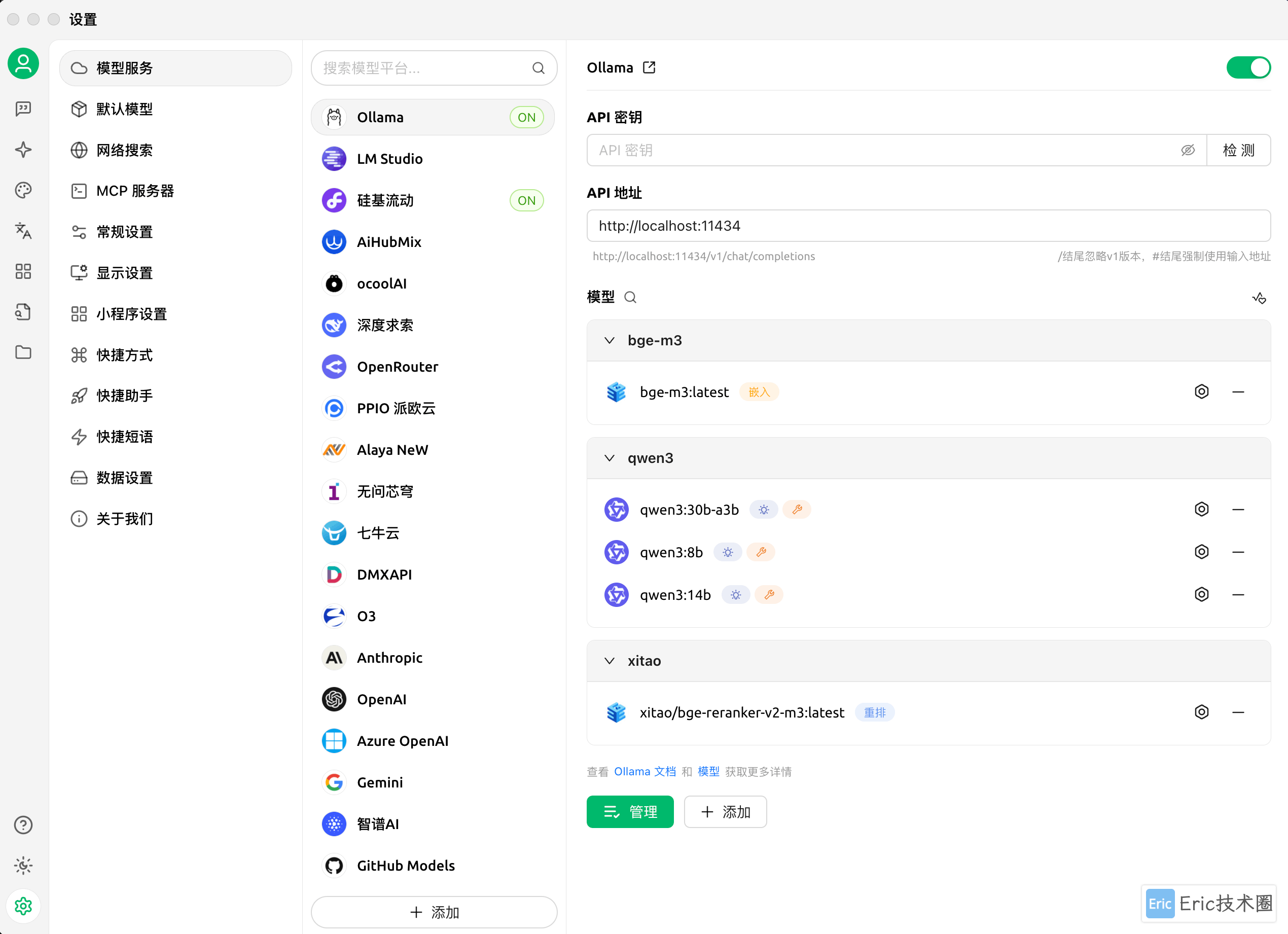
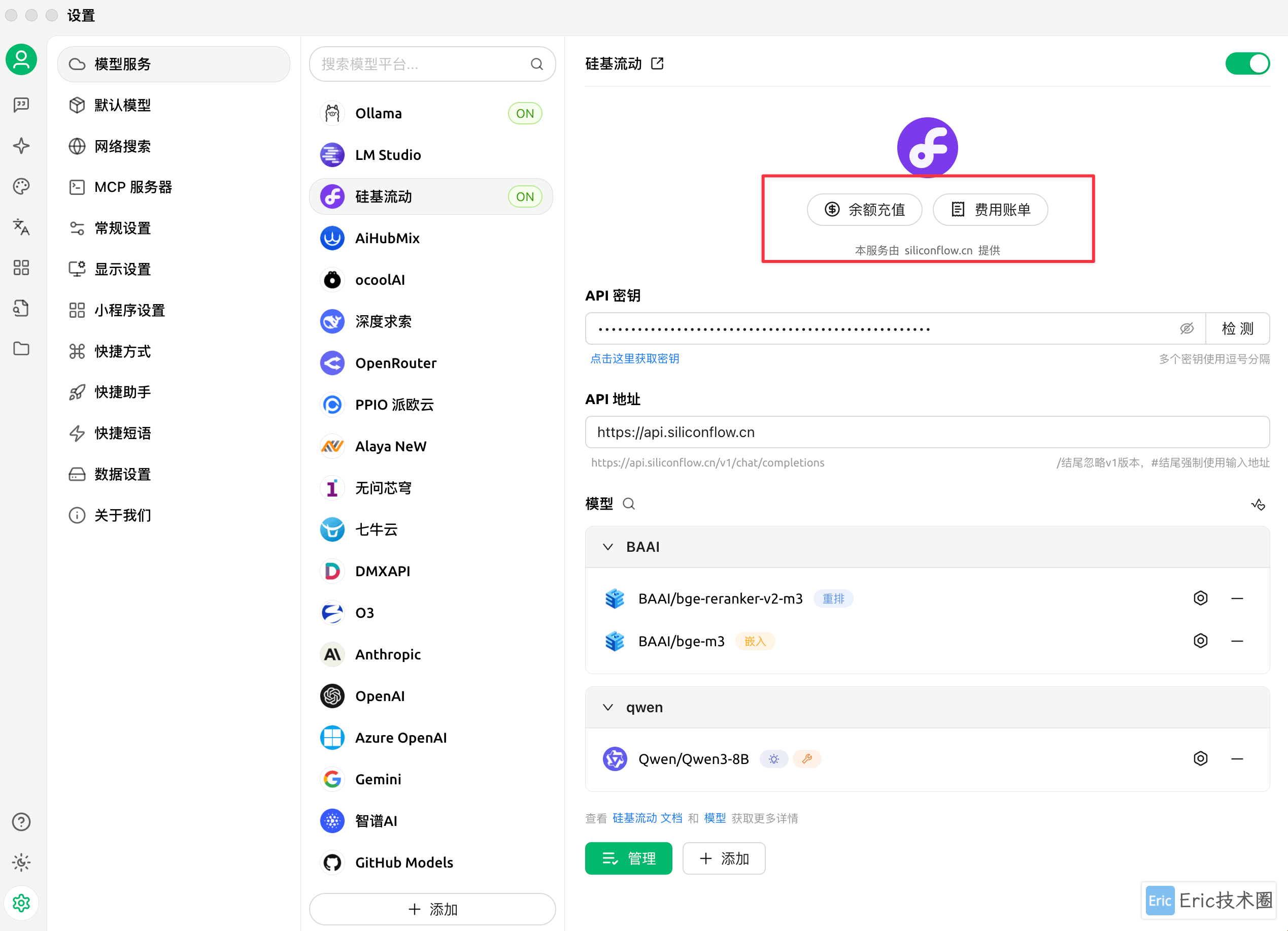
值得一提的是,硅基流动平台使用非常方便,直接登录即可获取 API key,无需额外在网页操作。本文将主要使用硅基流动进行演示,因为其响应速度明显更快,能够达到约 50 token/秒,而 Ollama 大约只有 10 token/秒。有趣的是,Ollama 在终端直接输出时速度却很快,这可能与模型推理过程和 Ollama 集成优化不足有关。
在硅基流动官网可以看到,qwen3-8b 和 bge 模型都是免费提供的:
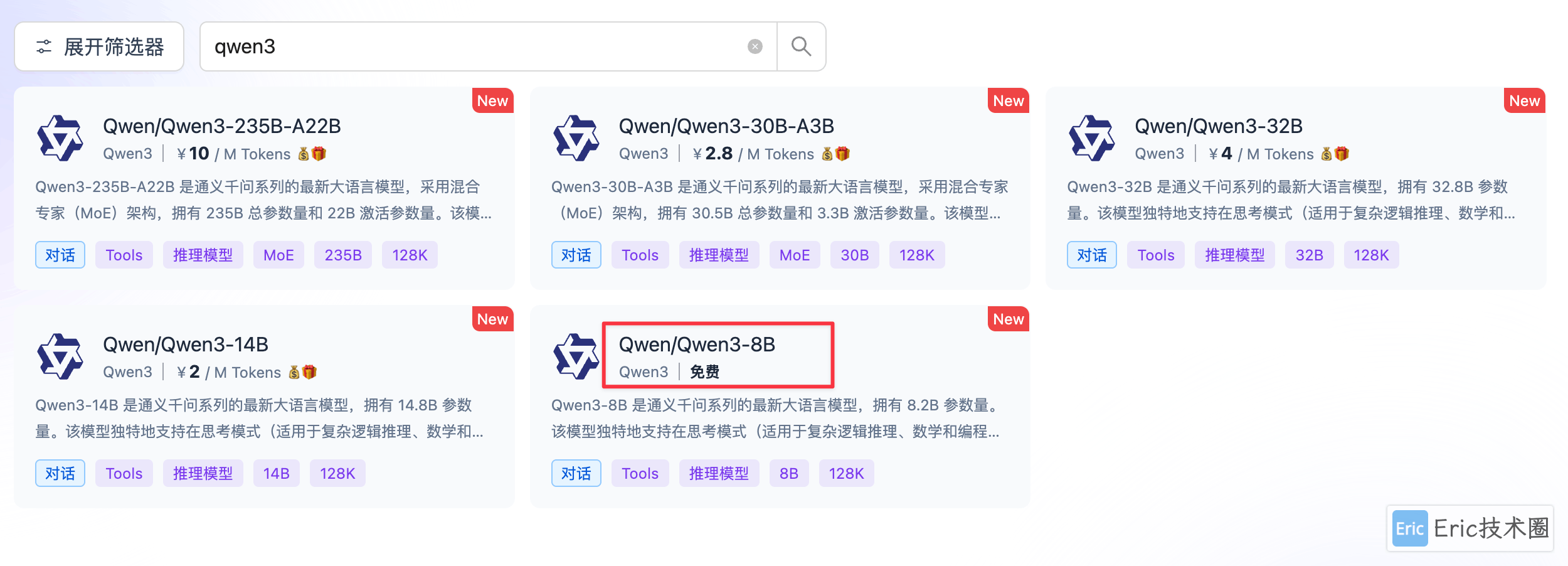
如何选择取决于对于个人数据是否想要完全私有化,完全私有化,可以选择 ollama,但是对于不懂技术,只想要快速使用的用户来说,可以直接在应用中注册网云平台免费使用,前面提到过,会将本地知识库检索出来的部分数据,推给远程的大语言模型 API,来生成最终结果。
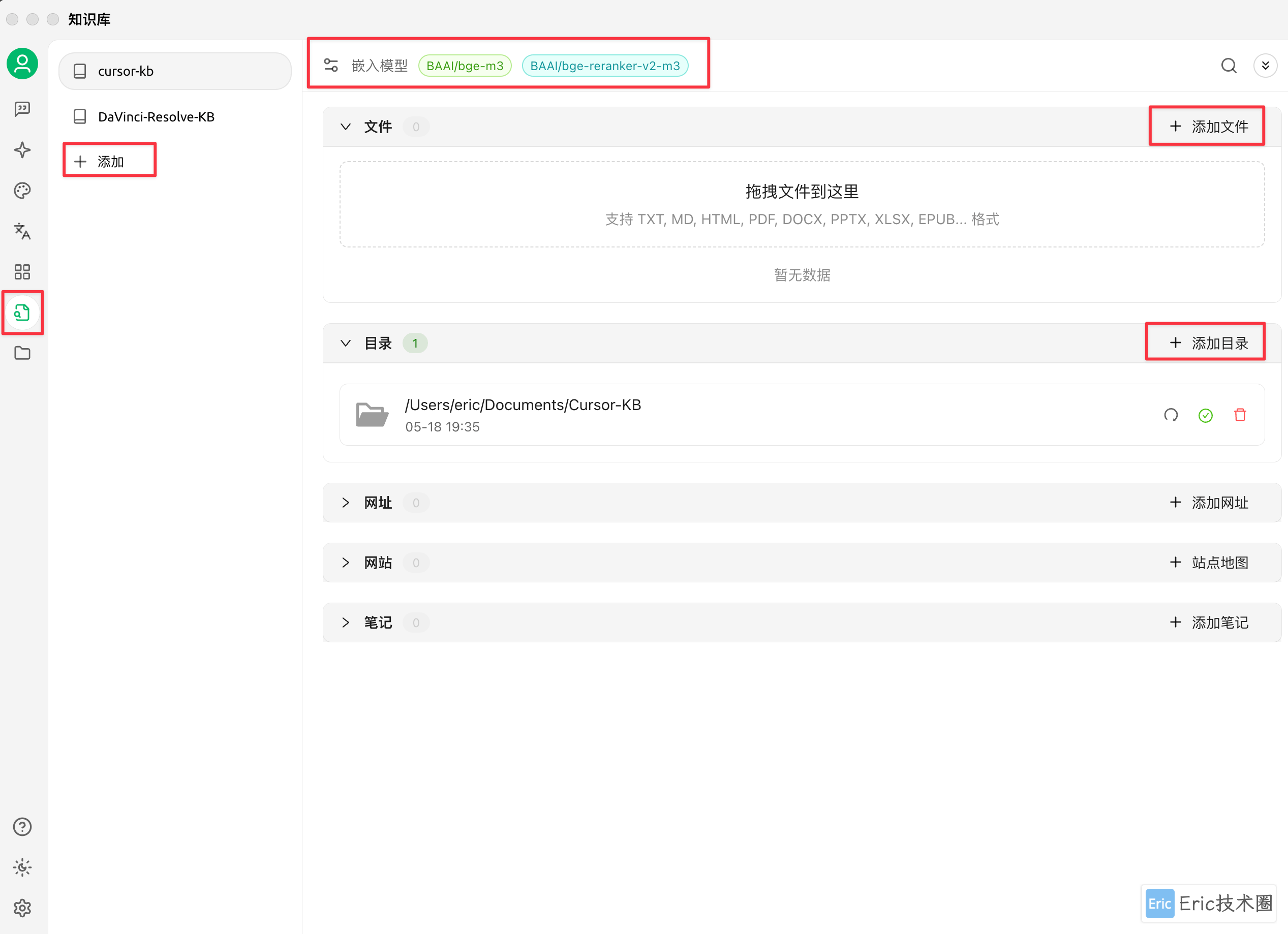
02 新建知识库
接下来填入知识库名称,选择合适的嵌入模型和重排模型。创建好知识库后,就可以方便地添加文档了。应用支持多种格式,最实用的功能是可以直接添加整个目录,然后等待系统完成嵌入和保存:
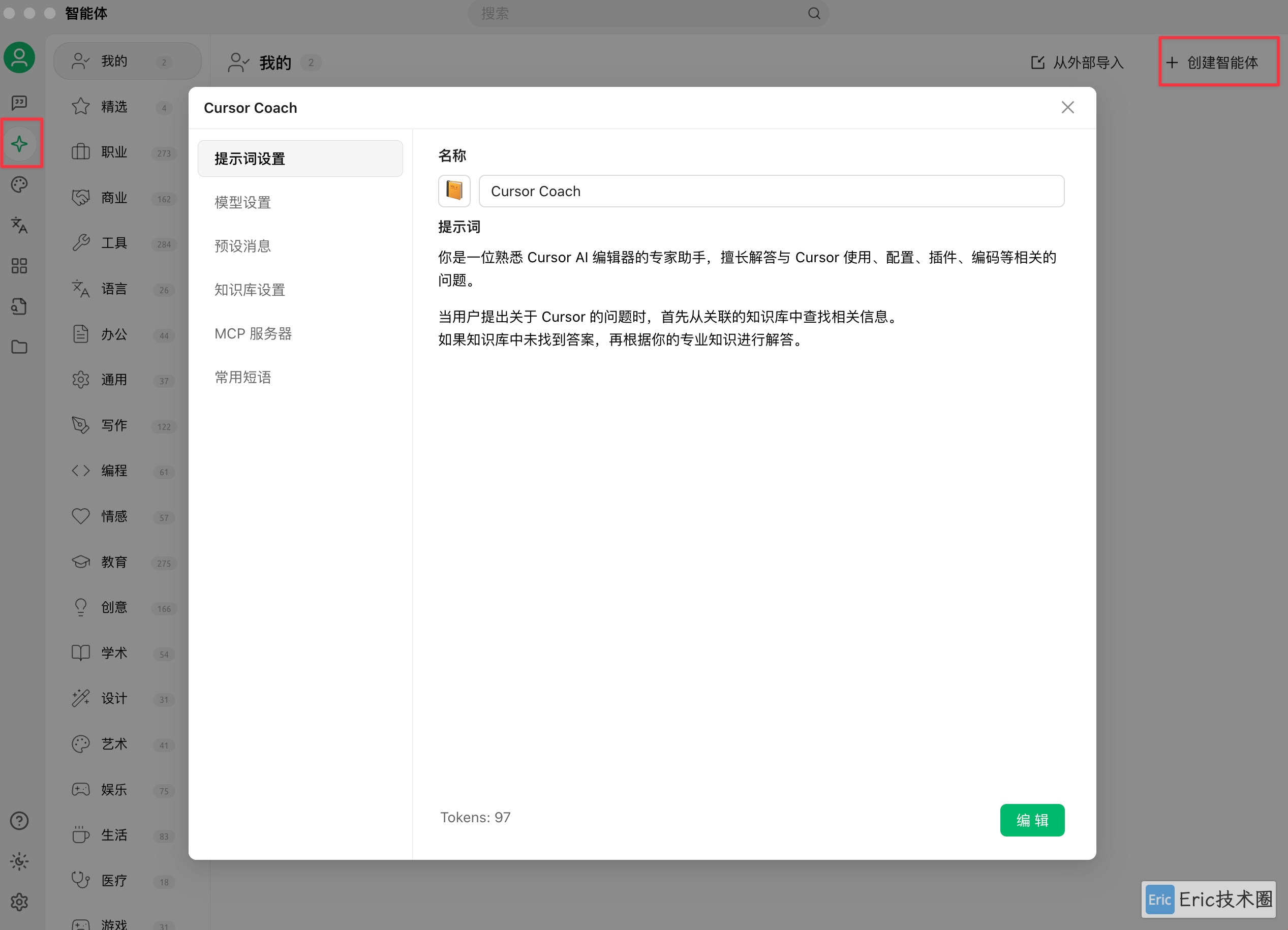
03 新建智能体
输入智能体名称、设置提示词,并选择刚才创建好的知识库。以下是一个核心提示词示例:
你是一位熟悉 Cursor AI 编辑器的专家助手,擅长解答与 Cursor 使用、配置、插件、编码等相关的问题。
当用户提出关于 Cursor 的问题时,首先从关联的知识库中查找相关信息。
如果知识库中未找到答案,再根据你的专业知识进行解答。如果你配置了支持网络查询的 MCP 工具,效果会更好——可以修改提示词,让智能体先查询本地知识库,查询不到时再进行联网查询。这样可以有效避免大语言模型在缺乏信息时产生的"幻觉"问题(因为大模型的训练数据通常较为滞后)。
默认选择 qwen3-8b 模型,重要提示:将模型温度设置为 0。这样可以让模型严格基于事实回答,在知识库查询不到信息时不会创造性地回答,从而避免生成错误信息或答非所问。
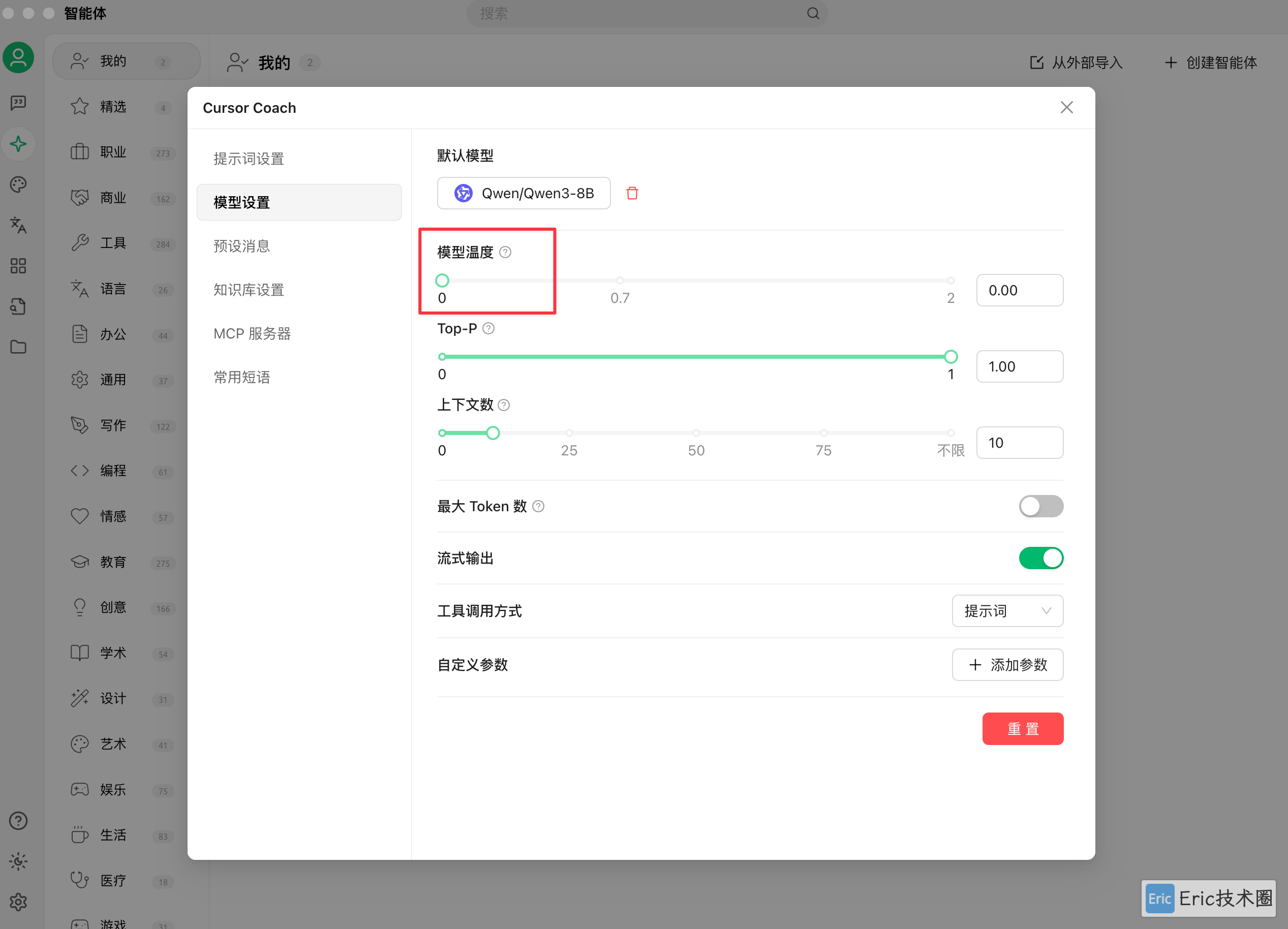
在知识库设置中,记得选择并连接你之前创建好的知识库。
04 聊天框中测试
最后,将智能体添加到聊天框中,开始进行提问测试:
现在,你可以自由地向知识库提问了:
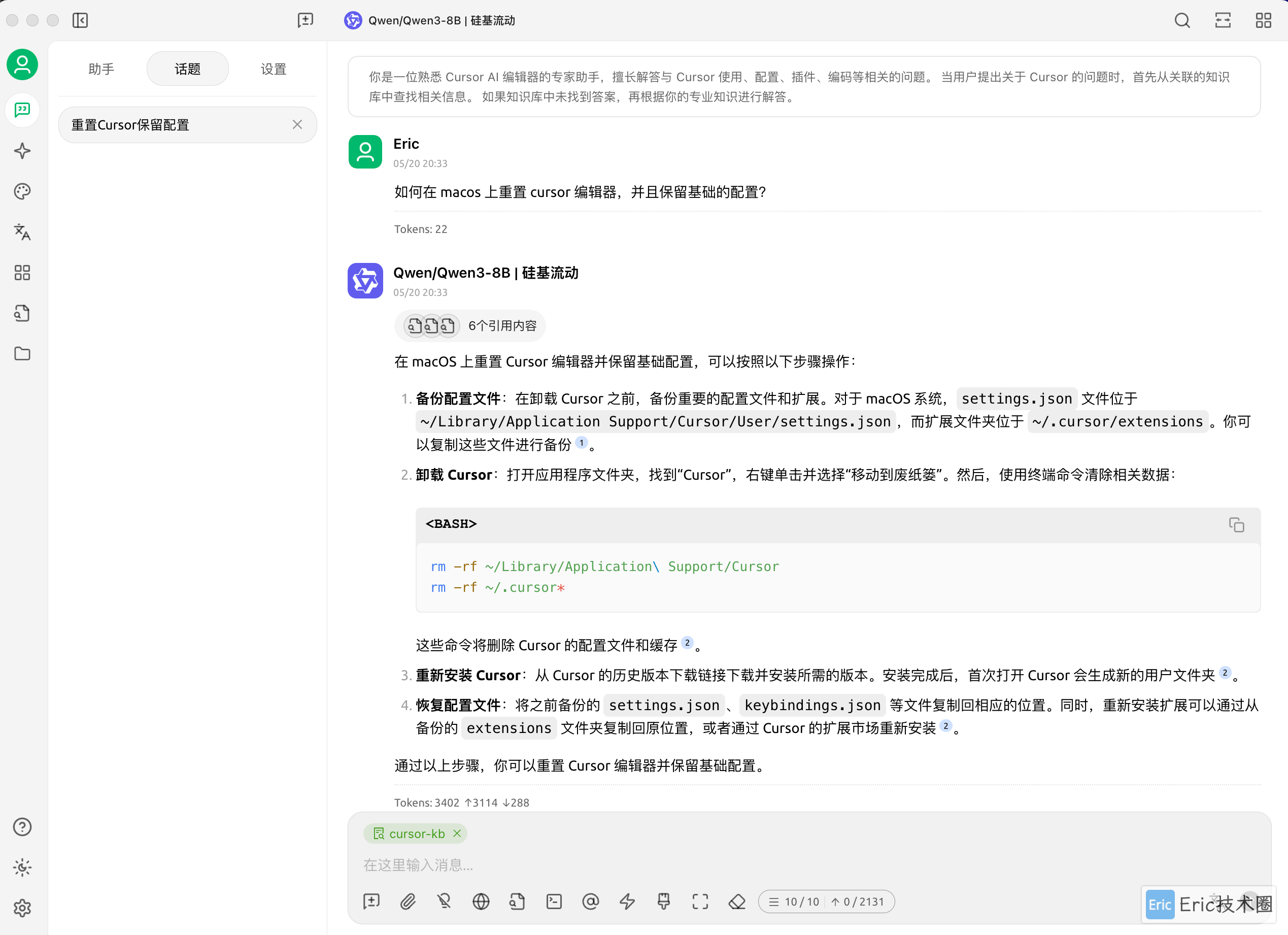
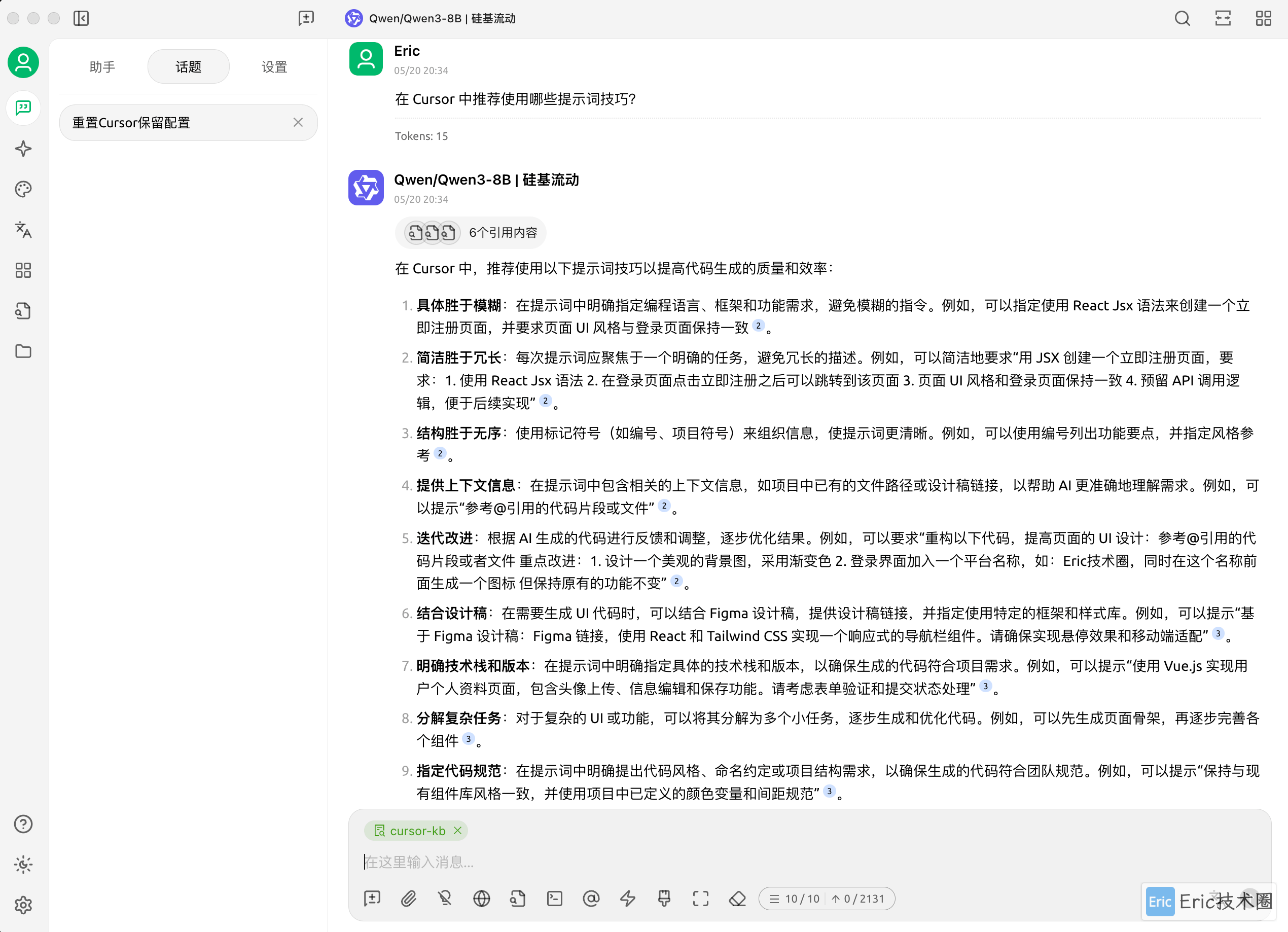
你还可以随时切换到 Ollama 本地模型进行回答,体验不同模型之间的差异:
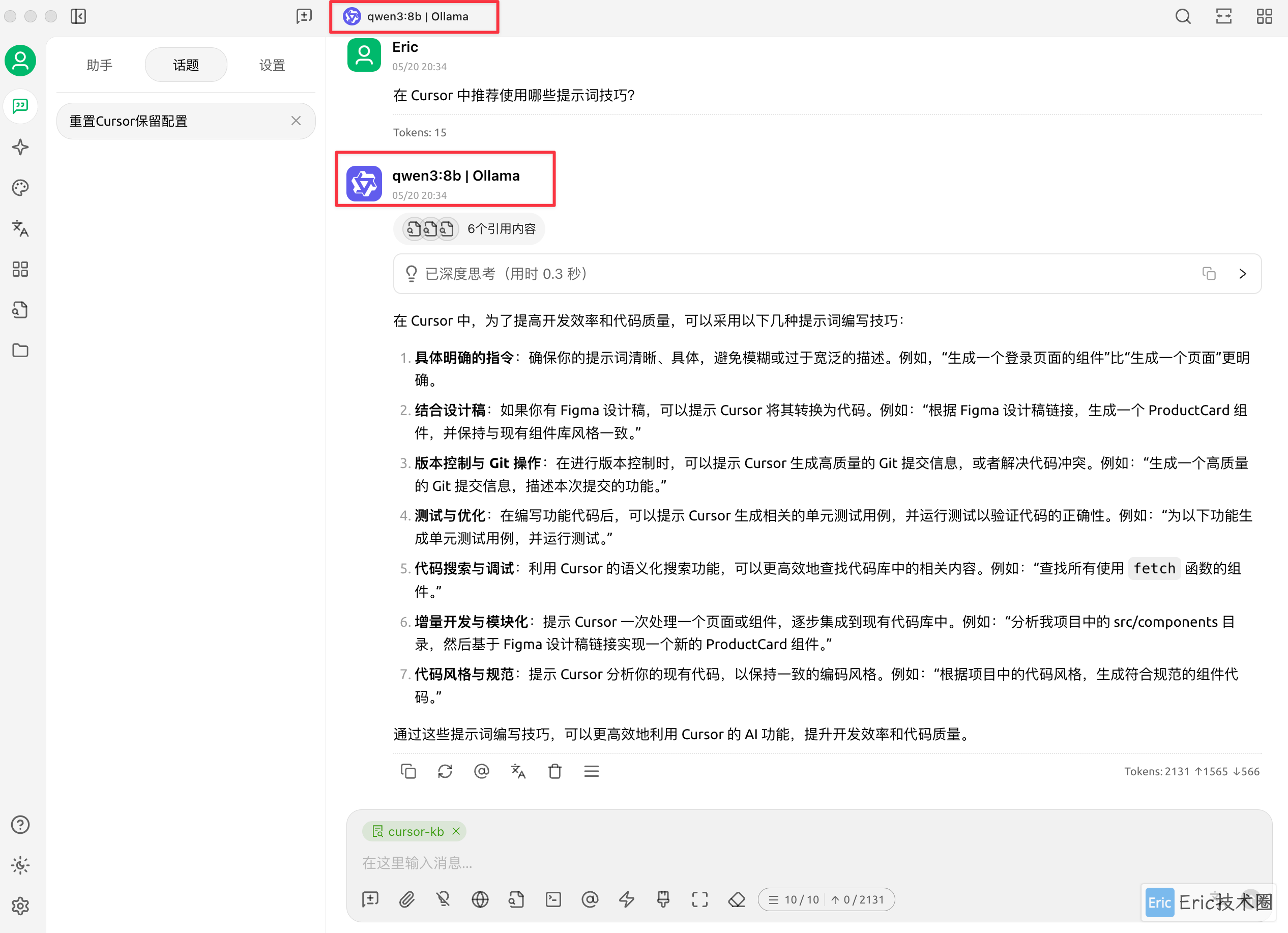
最后
通过本文介绍的方法,你现在已经拥有了一个功能完善、响应迅速的本地 AI 知识库。这套系统特别适合以下场景:
个人知识管理:将散落各处的笔记、文档集中管理,快速检索
专业领域学习:导入专业书籍、论文,进行深入问答
工作效率提升:快速查找项目文档、会议记录等信息
内容创作辅助:基于已有知识生成写作素材、构思创意
相比云端 AI 服务,本地知识库有几个明显优势:
数据安全:敏感信息不会上传到外部服务器
无需联网:离线环境下也能正常工作
无使用限制:不受API调用次数或字数限制
完全掌控:可以根据需要自由调整系统配置
当然,这个系统还有很多可以优化的空间。例如,你可以尝试更大参数量的模型(如果硬件允许)、调整知识库分块策略、优化提示词设计等。随着开源模型的不断进步,这套系统的能力还将持续提升。
希望这篇教程对你有所帮助。如果你在搭建过程中遇到任何问题,或者有改进建议,欢迎在评论区留言交流!
Cursor 系列精选阅读
如果你对 Cursor AI 编程感兴趣,可以浏览我的更多专题文章,同时我也会不定期地更新到视频号,欢迎观看和订阅。
🚀 快速上手
💻 开发环境配置
🔌 MCP 工具生态
📝 规范与项目管理
🎨 UI/UX 设计流程
🔬 实战案例
欢迎关注我的公众号"Eric技术圈",原创技术文章第一时间推送。